Softmax-free Linear Transformers
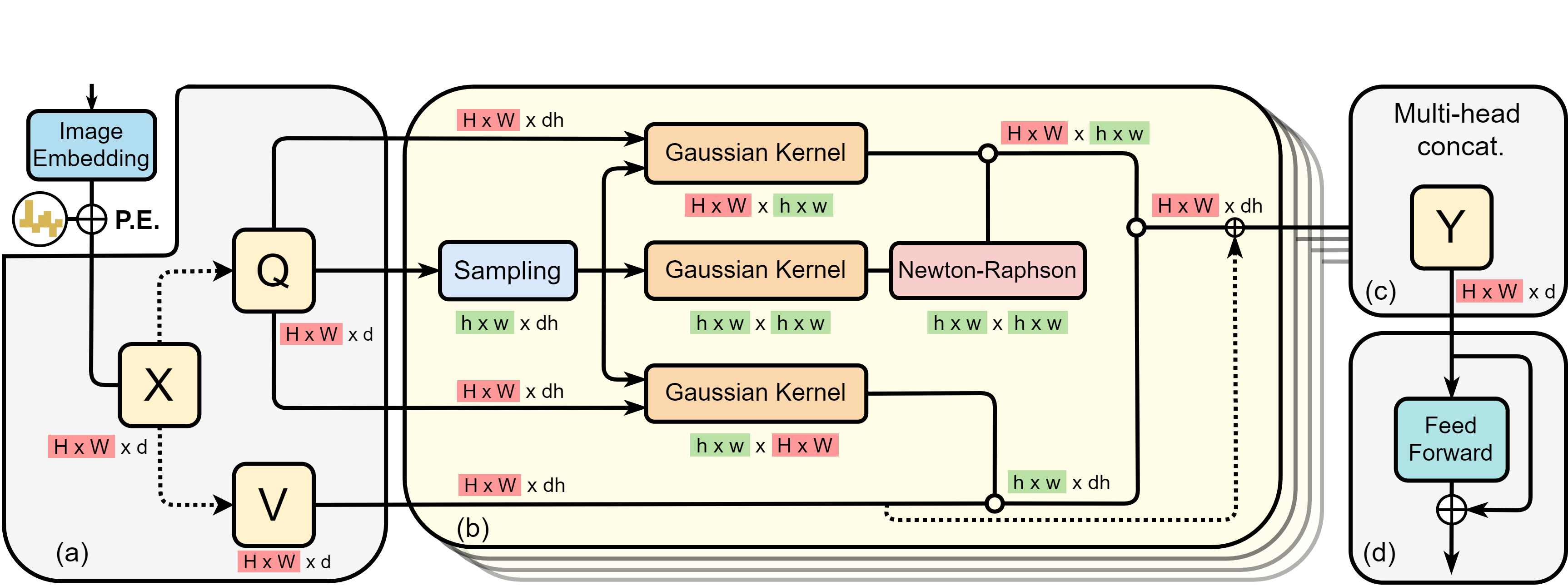
Vision transformers (ViTs) have pushed the state-of-the-art for visual perception tasks. The self-attention mechanism underpinning the strength of ViTs has a quadratic complexity in both computation and memory usage. This motivates the development of approximating the self-attention at linear complexity. However, an in-depth analysis in this work reveals that existing methods are either theoretically flawed or empirically ineffective for visual recognition. We identify that their limitations are rooted in the inheritance of softmax-based self-attention during approximations, that is, normalizing the scaled dot-product between token feature vectors using the softmax function. As preserving the softmax operation challenges any subsequent linearization efforts. By this insight, a family of Softmax-Free Transformers (SOFT) are proposed. Specifically, a Gaussian kernel function is adopted to replace the dot-product similarity, enabling a full self-attention matrix to be approximated under low-rank matrix decomposition. For computational robustness, we estimate the Moore-Penrose inverse using an iterative Newton-Raphson method in the forward process only, while calculating its theoretical gradients only once in the backward process. To further expand applicability (e.g., dense prediction tasks), an efficient symmetric normalization technique is introduced. Extensive experiments on ImageNet, COCO, and ADE20K show that our SOFT significantly improves the computational efficiency of existing ViT variants. With linear complexity, much longer token sequences are permitted by SOFT, resulting in superior trade-off between accuracy and complexity. Code and models are available at https://github.com/fudan-zvg/SOFT.
PDF Abstract

 ImageNet
ImageNet
 MS COCO
MS COCO
 Cityscapes
Cityscapes
 ListOps
ListOps
