Word Acquisition in Neural Language Models
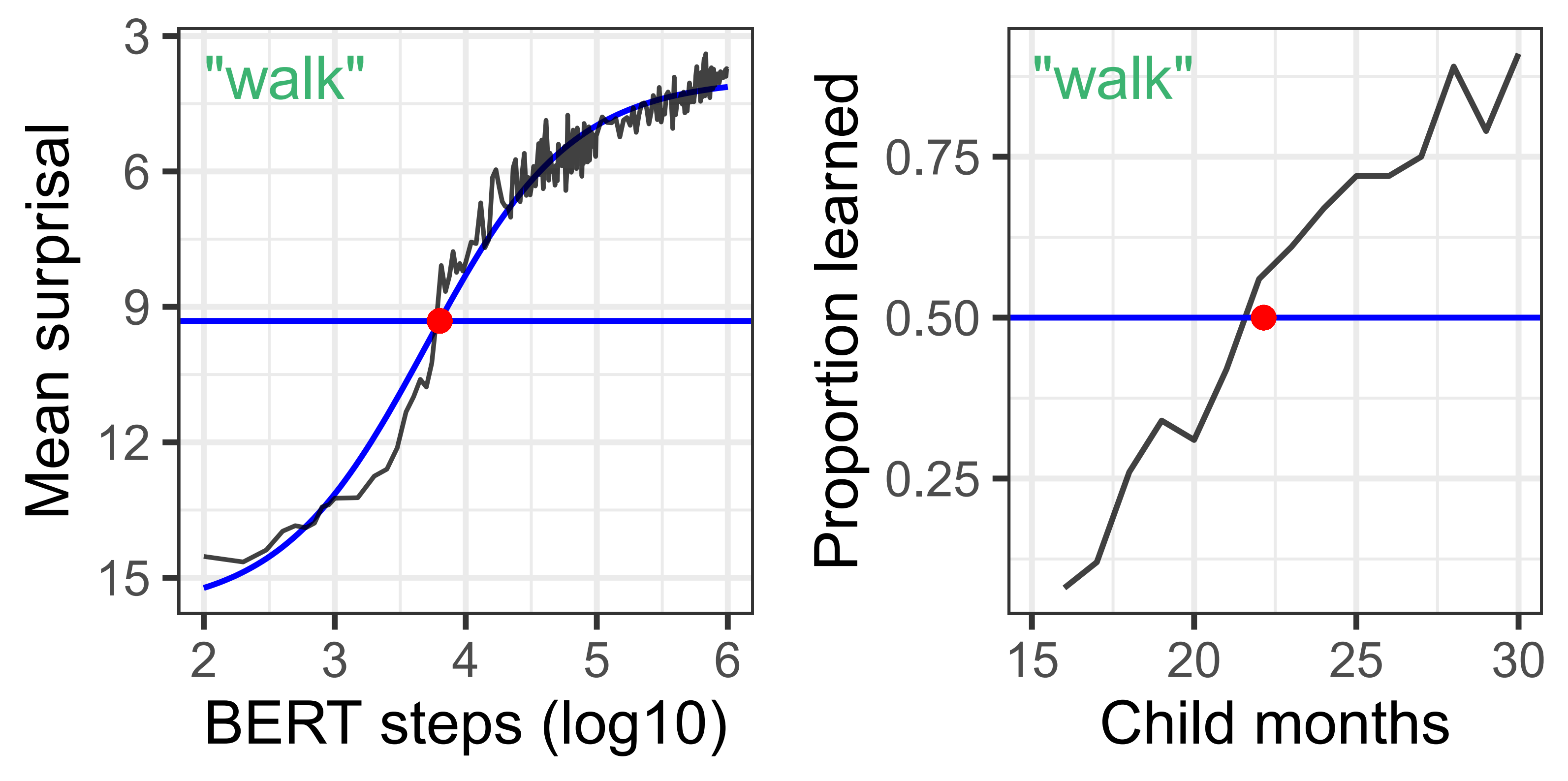
We investigate how neural language models acquire individual words during training, extracting learning curves and ages of acquisition for over 600 words on the MacArthur-Bates Communicative Development Inventory (Fenson et al., 2007). Drawing on studies of word acquisition in children, we evaluate multiple predictors for words' ages of acquisition in LSTMs, BERT, and GPT-2. We find that the effects of concreteness, word length, and lexical class are pointedly different in children and language models, reinforcing the importance of interaction and sensorimotor experience in child language acquisition. Language models rely far more on word frequency than children, but like children, they exhibit slower learning of words in longer utterances. Interestingly, models follow consistent patterns during training for both unidirectional and bidirectional models, and for both LSTM and Transformer architectures. Models predict based on unigram token frequencies early in training, before transitioning loosely to bigram probabilities, eventually converging on more nuanced predictions. These results shed light on the role of distributional learning mechanisms in children, while also providing insights for more human-like language acquisition in language models.
PDF Abstract

