 Off-Policy TD Control
Off-Policy TD Control
Double Q-learning
Introduced by Hasselt in Double Q-learningDouble Q-learning is an off-policy reinforcement learning algorithm that utilises double estimation to counteract overestimation problems with traditional Q-learning.
The max operator in standard Q-learning and DQN uses the same values both to select and to evaluate an action. This makes it more likely to select overestimated values, resulting in overoptimistic value estimates. To prevent this, we can decouple the selection from the evaluation, which is the idea behind Double Q-learning:
$$ Y^{Q}_{t} = R_{t+1} + \gamma{Q}\left(S_{t+1}, \arg\max_{a}Q\left(S_{t+1}, a; \mathbb{\theta}_{t}\right);\mathbb{\theta}_{t}\right) $$
The Double Q-learning error can then be written as:
$$ Y^{DoubleQ}_{t} = R_{t+1} + \gamma{Q}\left(S_{t+1}, \arg\max_{a}Q\left(S_{t+1}, a; \mathbb{\theta}_{t}\right);\mathbb{\theta}^{'}_{t}\right) $$
Here the selection of the action in the $\arg\max$ is still due to the online weights $\theta_{t}$. But we use a second set of weights $\mathbb{\theta}^{'}_{t}$ to fairly evaluate the value of this policy.
Source: Deep Reinforcement Learning with Double Q-learning
Source: Double Q-learning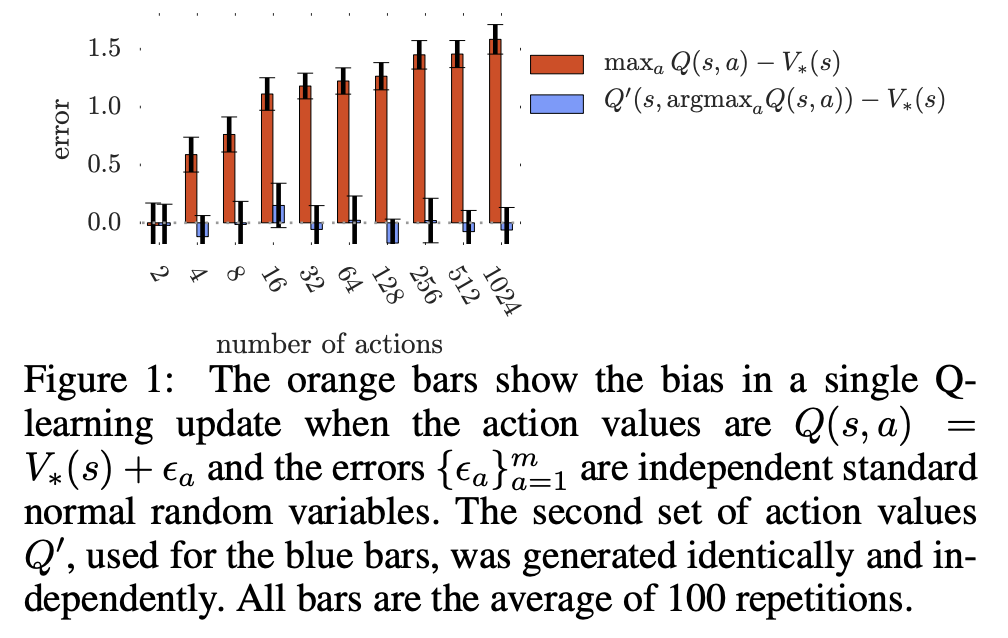
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Reinforcement Learning (RL) | 69 | 43.40% |
| Atari Games | 18 | 11.32% |
| OpenAI Gym | 10 | 6.29% |
| Decision Making | 9 | 5.66% |
| Continuous Control | 7 | 4.40% |
| Management | 4 | 2.52% |
| Multi-agent Reinforcement Learning | 4 | 2.52% |
| Efficient Exploration | 3 | 1.89% |
| Ensemble Learning | 2 | 1.26% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
