 Policy Gradient Methods
Policy Gradient Methods
Soft Actor Critic
Introduced by Haarnoja et al. in Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic ActorSoft Actor Critic, or SAC, is an off-policy actor-critic deep RL algorithm based on the maximum entropy reinforcement learning framework. In this framework, the actor aims to maximize expected reward while also maximizing entropy. That is, to succeed at the task while acting as randomly as possible. Prior deep RL methods based on this framework have been formulated as Q-learning methods. SAC combines off-policy updates with a stable stochastic actor-critic formulation.
The SAC objective has a number of advantages. First, the policy is incentivized to explore more widely, while giving up on clearly unpromising avenues. Second, the policy can capture multiple modes of near-optimal behavior. In problem settings where multiple actions seem equally attractive, the policy will commit equal probability mass to those actions. Lastly, the authors present evidence that it improves learning speed over state-of-art methods that optimize the conventional RL objective function.
Source: Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor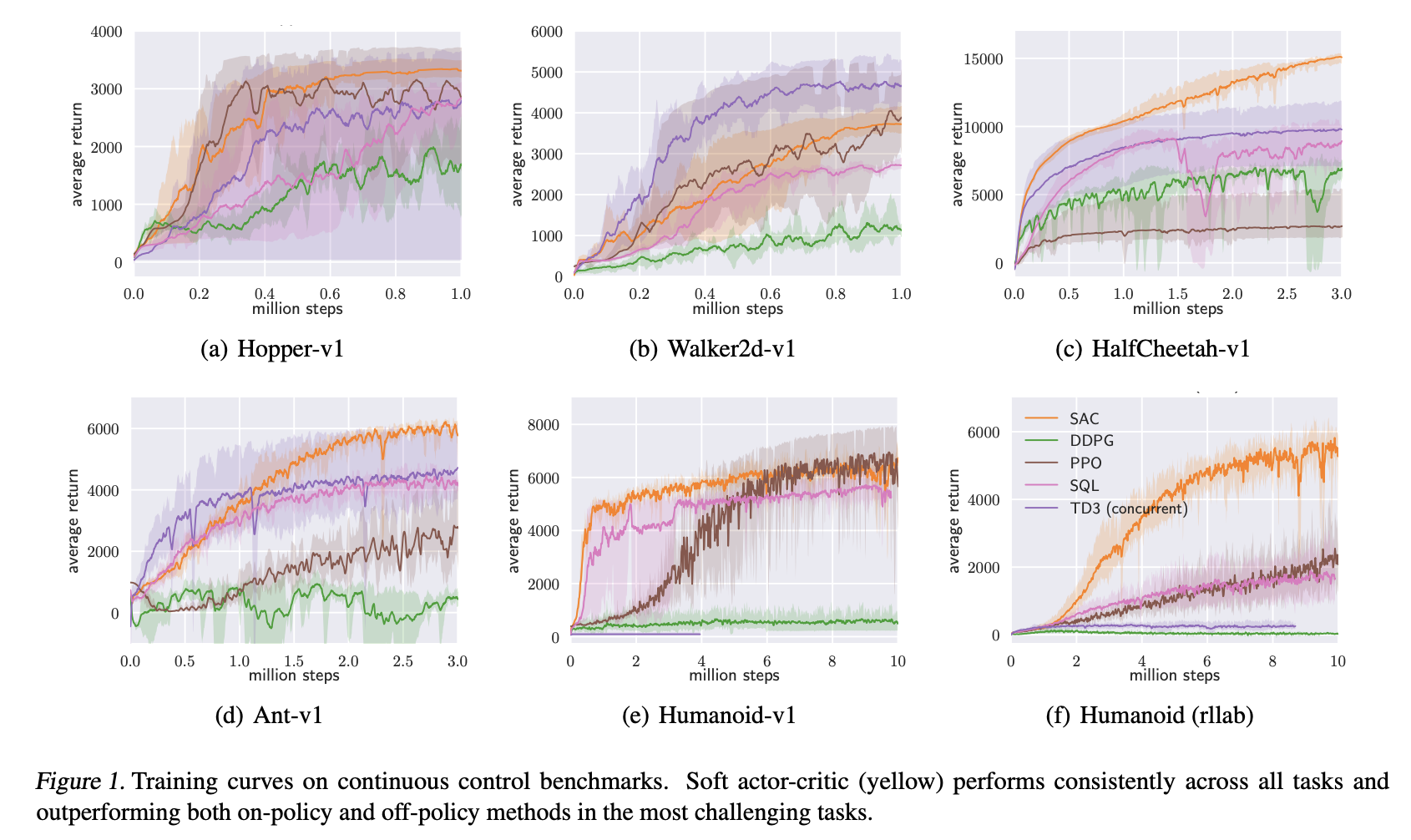
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Reinforcement Learning (RL) | 27 | 36.49% |
| Continuous Control | 12 | 16.22% |
| Imitation Learning | 4 | 5.41% |
| Decision Making | 4 | 5.41% |
| OpenAI Gym | 4 | 5.41% |
| Efficient Exploration | 3 | 4.05% |
| Motion Planning | 2 | 2.70% |
| Model-based Reinforcement Learning | 2 | 2.70% |
| Fairness | 1 | 1.35% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
 Adam
Adam
|
Stochastic Optimization | |
 Dense Connections
Dense Connections
|
Feedforward Networks | |
 Experience Replay
Experience Replay
|
Replay Memory | |
 ReLU
ReLU
|
Activation Functions |
