Betrayed by Captions: Joint Caption Grounding and Generation for Open Vocabulary Instance Segmentation
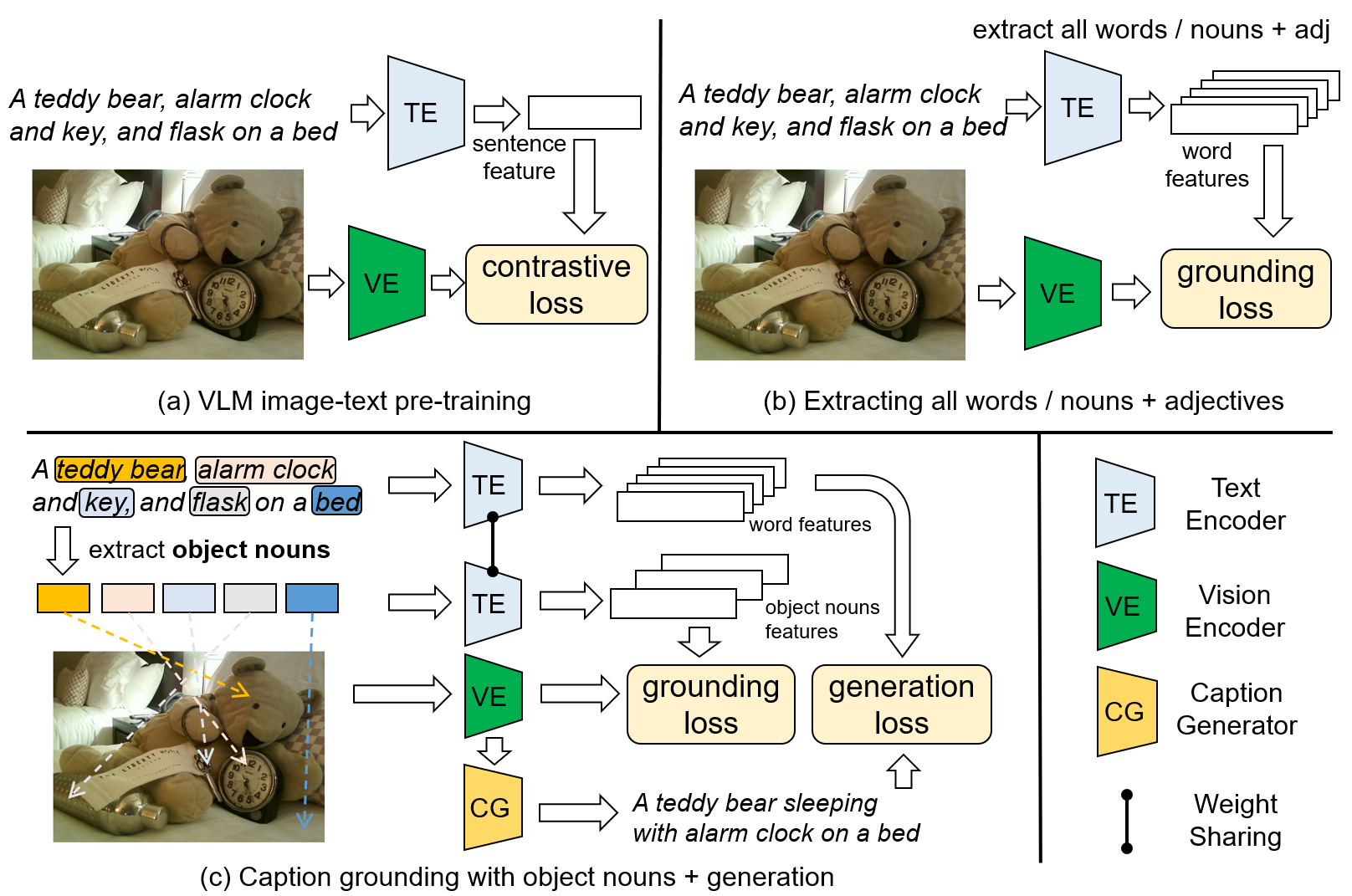
In this work, we focus on open vocabulary instance segmentation to expand a segmentation model to classify and segment instance-level novel categories. Previous approaches have relied on massive caption datasets and complex pipelines to establish one-to-one mappings between image regions and words in captions. However, such methods build noisy supervision by matching non-visible words to image regions, such as adjectives and verbs. Meanwhile, context words are also important for inferring the existence of novel objects as they show high inter-correlations with novel categories. To overcome these limitations, we devise a joint \textbf{Caption Grounding and Generation (CGG)} framework, which incorporates a novel grounding loss that only focuses on matching object nouns to improve learning efficiency. We also introduce a caption generation head that enables additional supervision and contextual modeling as a complementation to the grounding loss. Our analysis and results demonstrate that grounding and generation components complement each other, significantly enhancing the segmentation performance for novel classes. Experiments on the COCO dataset with two settings: Open Vocabulary Instance Segmentation (OVIS) and Open Set Panoptic Segmentation (OSPS) demonstrate the superiority of the CGG. Specifically, CGG achieves a substantial improvement of 6.8% mAP for novel classes without extra data on the OVIS task and 15% PQ improvements for novel classes on the OSPS benchmark.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract




 ImageNet
ImageNet
 MS COCO
MS COCO
 ADE20K
ADE20K
 LVIS
LVIS
 Conceptual Captions
Conceptual Captions
