Building Cooperative Embodied Agents Modularly with Large Language Models
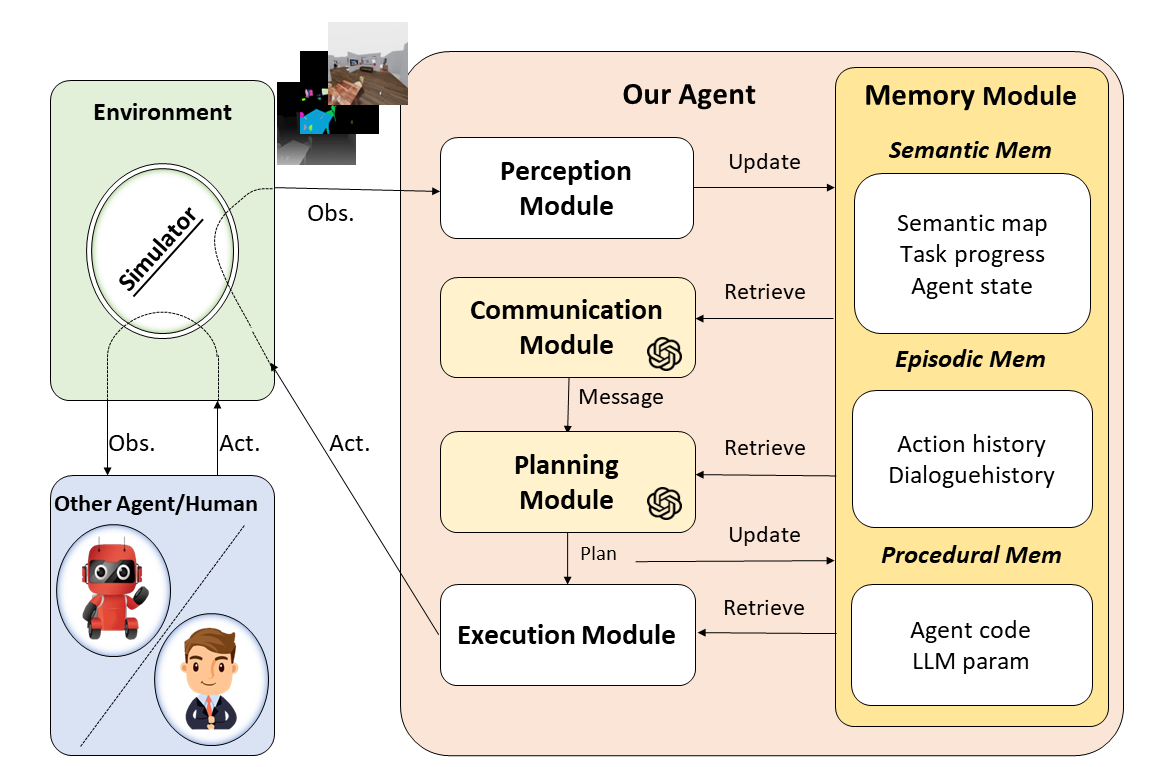
In this work, we address challenging multi-agent cooperation problems with decentralized control, raw sensory observations, costly communication, and multi-objective tasks instantiated in various embodied environments. While previous research either presupposes a cost-free communication channel or relies on a centralized controller with shared observations, we harness the commonsense knowledge, reasoning ability, language comprehension, and text generation prowess of LLMs and seamlessly incorporate them into a cognitive-inspired modular framework that integrates with perception, memory, and execution. Thus building a Cooperative Embodied Language Agent CoELA, who can plan, communicate, and cooperate with others to accomplish long-horizon tasks efficiently. Our experiments on C-WAH and TDW-MAT demonstrate that CoELA driven by GPT-4 can surpass strong planning-based methods and exhibit emergent effective communication. Though current Open LMs like LLAMA-2 still underperform, we fine-tune a CoELA with data collected with our agents and show how they can achieve promising performance. We also conducted a user study for human-agent interaction and discovered that CoELA communicating in natural language can earn more trust and cooperate more effectively with humans. Our research underscores the potential of LLMs for future research in multi-agent cooperation. Videos can be found on the project website https://vis-www.cs.umass.edu/Co-LLM-Agents/.
PDF Abstract

 ThreeDWorld Transport Challenge
ThreeDWorld Transport Challenge
