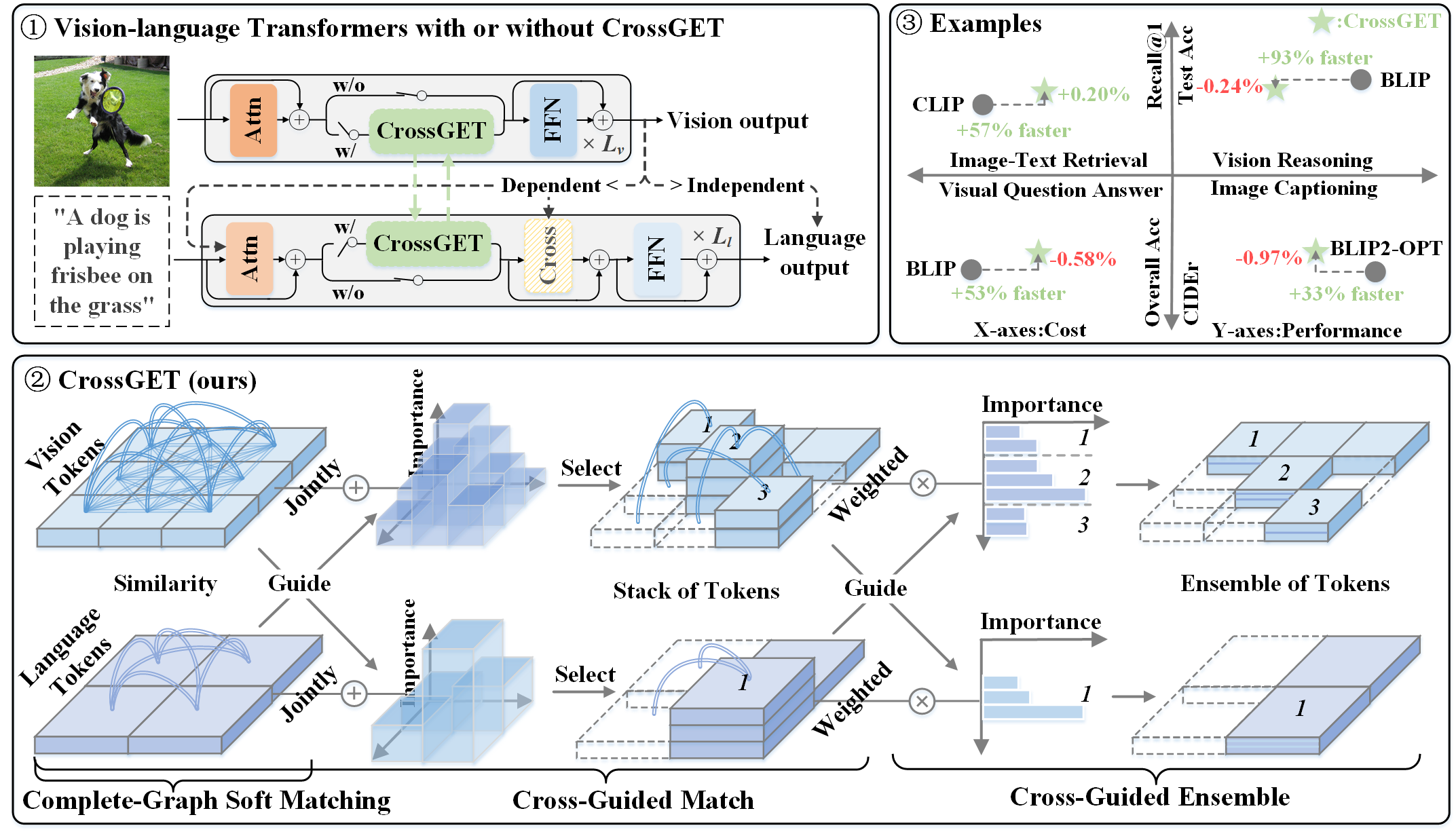
CrossGET: Cross-Guided Ensemble of Tokens for Accelerating Vision-Language Transformers
Recent vision-language models have achieved tremendous progress far beyond what we ever expected. However, their computational costs are also dramatically growing with rapid development, especially for the large models. It makes model acceleration exceedingly critical in a scenario of limited resources. Although extensively studied for unimodal models, the acceleration for multimodal models, especially the vision-language Transformers, is relatively under-explored. To pursue more efficient and accessible vision-language Transformers, this paper introduces \textbf{Cross}-\textbf{G}uided \textbf{E}nsemble of \textbf{T}okens (\textbf{\emph{CrossGET}}), a universal acceleration framework for vision-language Transformers. This framework adaptively combines tokens through real-time, cross-modal guidance, thereby achieving substantial acceleration while keeping high performance. \textit{CrossGET} has two key innovations: 1) \textit{Cross-Guided Matching and Ensemble}. \textit{CrossGET} incorporates cross-modal guided token matching and ensemble to exploit cross-modal information effectively, only introducing cross-modal tokens with negligible extra parameters. 2) \textit{Complete-Graph Soft Matching}. In contrast to the existing bipartite soft matching approach, \textit{CrossGET} introduces a complete-graph soft matching policy to achieve more reliable token-matching results while maintaining parallelizability and high efficiency. Extensive experiments are conducted on various vision-language tasks, including image-text retrieval, visual reasoning, image captioning, and visual question answering. Performance on both classic multimodal architectures and emerging multimodal LLMs demonstrate the effectiveness and versatility of the proposed \textit{CrossGET} framework. The code will be at \url{https://github.com/sdc17/CrossGET}.
PDF Abstract




 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 Flickr30k
Flickr30k
 Visual Question Answering v2.0
Visual Question Answering v2.0
 NoCaps
NoCaps
 NLVR
NLVR
