DeepSolo++: Let Transformer Decoder with Explicit Points Solo for Multilingual Text Spotting
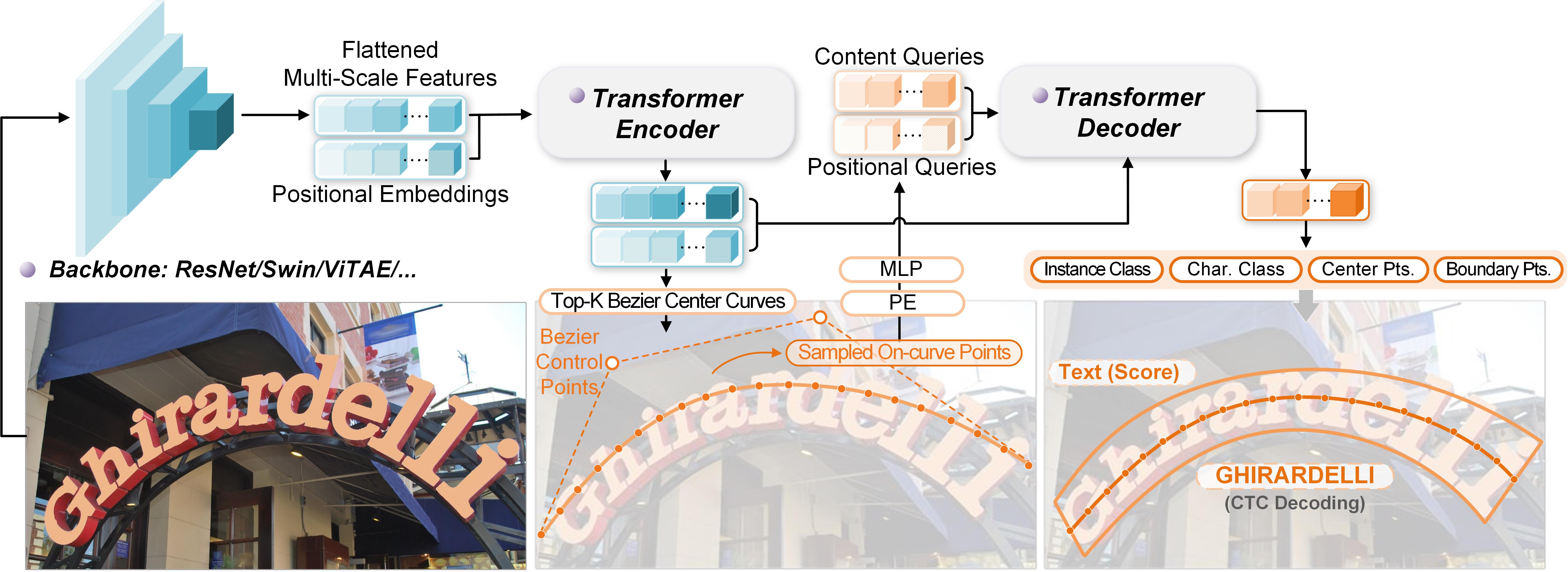
End-to-end text spotting aims to integrate scene text detection and recognition into a unified framework. Dealing with the relationship between the two sub-tasks plays a pivotal role in designing effective spotters. Although Transformer-based methods eliminate the heuristic post-processing, they still suffer from the synergy issue between the sub-tasks and low training efficiency. Besides, they overlook the exploring on multilingual text spotting which requires an extra script identification task. In this paper, we present DeepSolo++, a simple DETR-like baseline that lets a single decoder with explicit points solo for text detection, recognition, and script identification simultaneously. Technically, for each text instance, we represent the character sequence as ordered points and model them with learnable explicit point queries. After passing a single decoder, the point queries have encoded requisite text semantics and locations, thus can be further decoded to the center line, boundary, script, and confidence of text via very simple prediction heads in parallel. Furthermore, we show the surprisingly good extensibility of our method, in terms of character class, language type, and task. On the one hand, our method not only performs well in English scenes but also masters the transcription with complex font structure and a thousand-level character classes, such as Chinese. On the other hand, our DeepSolo++ achieves better performance on the additionally introduced script identification task with a simpler training pipeline compared with previous methods. In addition, our models are also compatible with line annotations, which require much less annotation cost than polygons. The code is available at \url{https://github.com/ViTAE-Transformer/DeepSolo}.
PDF Abstract

 SCUT-CTW1500
SCUT-CTW1500
 TextOCR
TextOCR

