IncepFormer: Efficient Inception Transformer with Pyramid Pooling for Semantic Segmentation
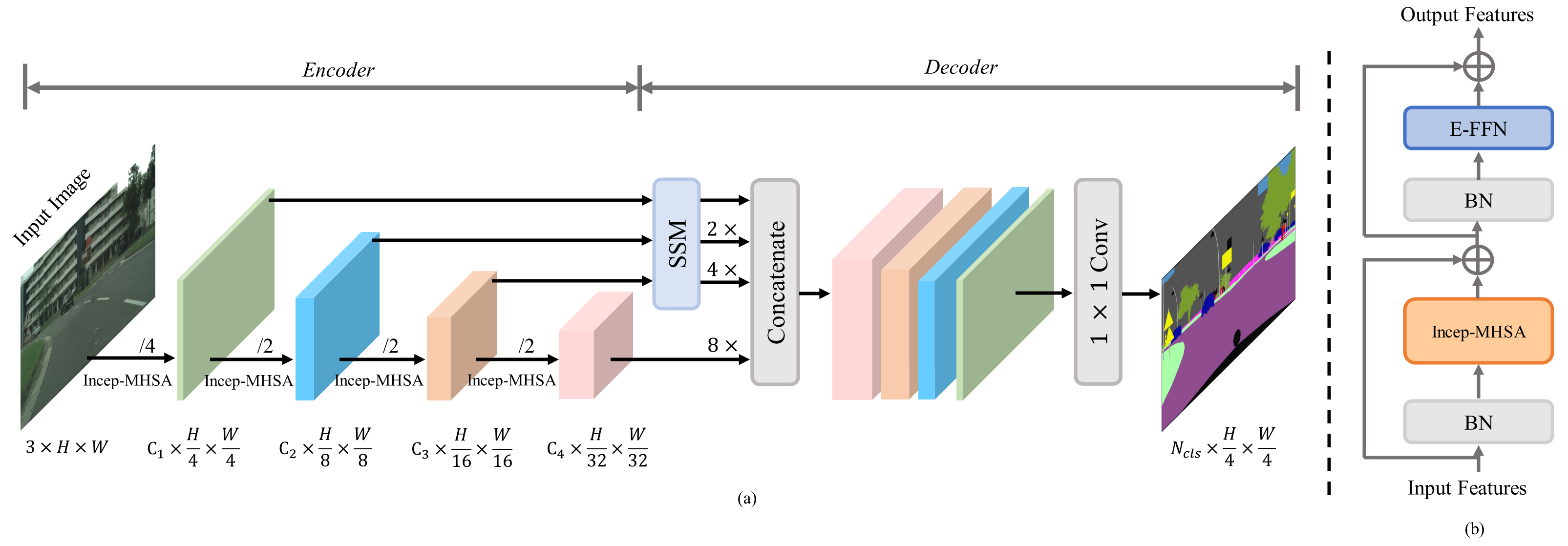
Semantic segmentation usually benefits from global contexts, fine localisation information, multi-scale features, etc. To advance Transformer-based segmenters with these aspects, we present a simple yet powerful semantic segmentation architecture, termed as IncepFormer. IncepFormer has two critical contributions as following. First, it introduces a novel pyramid structured Transformer encoder which harvests global context and fine localisation features simultaneously. These features are concatenated and fed into a convolution layer for final per-pixel prediction. Second, IncepFormer integrates an Inception-like architecture with depth-wise convolutions, and a light-weight feed-forward module in each self-attention layer, efficiently obtaining rich local multi-scale object features. Extensive experiments on five benchmarks show that our IncepFormer is superior to state-of-the-art methods in both accuracy and speed, e.g., 1) our IncepFormer-S achieves 47.7% mIoU on ADE20K which outperforms the existing best method by 1% while only costs half parameters and fewer FLOPs. 2) Our IncepFormer-B finally achieves 82.0% mIoU on Cityscapes dataset with 39.6M parameters. Code is available:github.com/shendu0321/IncepFormer.
PDF Abstract


 ImageNet
ImageNet
 Cityscapes
Cityscapes
 ADE20K
ADE20K

