MB-TaylorFormer: Multi-branch Efficient Transformer Expanded by Taylor Formula for Image Dehazing
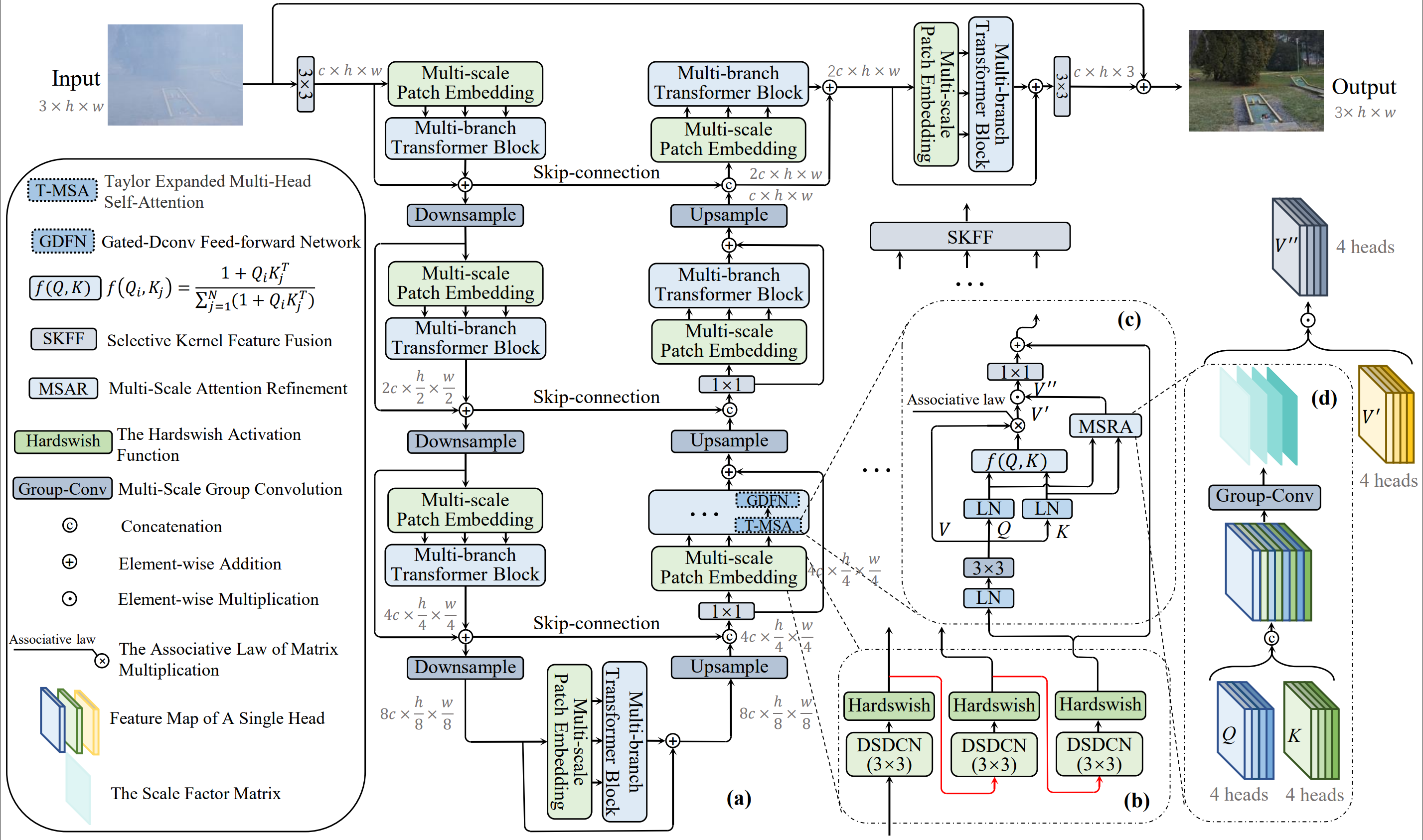
In recent years, Transformer networks are beginning to replace pure convolutional neural networks (CNNs) in the field of computer vision due to their global receptive field and adaptability to input. However, the quadratic computational complexity of softmax-attention limits the wide application in image dehazing task, especially for high-resolution images. To address this issue, we propose a new Transformer variant, which applies the Taylor expansion to approximate the softmax-attention and achieves linear computational complexity. A multi-scale attention refinement module is proposed as a complement to correct the error of the Taylor expansion. Furthermore, we introduce a multi-branch architecture with multi-scale patch embedding to the proposed Transformer, which embeds features by overlapping deformable convolution of different scales. The design of multi-scale patch embedding is based on three key ideas: 1) various sizes of the receptive field; 2) multi-level semantic information; 3) flexible shapes of the receptive field. Our model, named Multi-branch Transformer expanded by Taylor formula (MB-TaylorFormer), can embed coarse to fine features more flexibly at the patch embedding stage and capture long-distance pixel interactions with limited computational cost. Experimental results on several dehazing benchmarks show that MB-TaylorFormer achieves state-of-the-art (SOTA) performance with a light computational burden. The source code and pre-trained models are available at https://github.com/FVL2020/ICCV-2023-MB-TaylorFormer.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract

 O-HAZE
O-HAZE
 RainCityscapes
RainCityscapes
