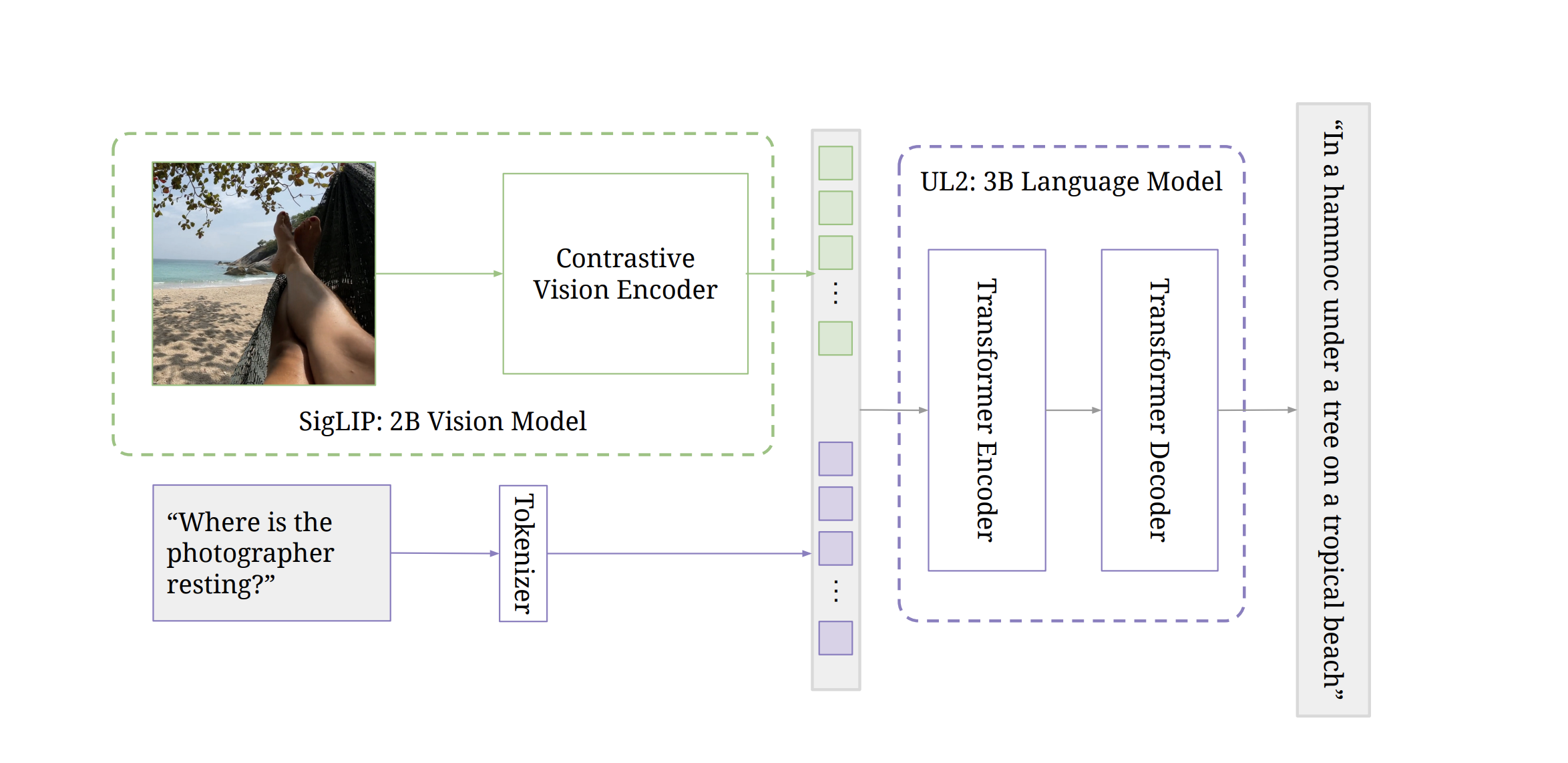
PaLI-3 Vision Language Models: Smaller, Faster, Stronger
This paper presents PaLI-3, a smaller, faster, and stronger vision language model (VLM) that compares favorably to similar models that are 10x larger. As part of arriving at this strong performance, we compare Vision Transformer (ViT) models pretrained using classification objectives to contrastively (SigLIP) pretrained ones. We find that, while slightly underperforming on standard image classification benchmarks, SigLIP-based PaLI shows superior performance across various multimodal benchmarks, especially on localization and visually-situated text understanding. We scale the SigLIP image encoder up to 2 billion parameters, and achieves a new state-of-the-art on multilingual cross-modal retrieval. We hope that PaLI-3, at only 5B parameters, rekindles research on fundamental pieces of complex VLMs, and could fuel a new generation of scaled-up models.
PDF AbstractCode






 CelebA
CelebA
 MSR-VTT
MSR-VTT
 OK-VQA
OK-VQA
 TextVQA
TextVQA
 VATEX
VATEX
 NExT-QA
NExT-QA
 ST-VQA
ST-VQA
 InfographicVQA
InfographicVQA
 MIAP
MIAP
Results from the Paper
 Ranked #2 on
Temporal/Casual QA
on NExT-QA
(using extra training data)
Ranked #2 on
Temporal/Casual QA
on NExT-QA
(using extra training data)
