PointCLIP V2: Prompting CLIP and GPT for Powerful 3D Open-world Learning
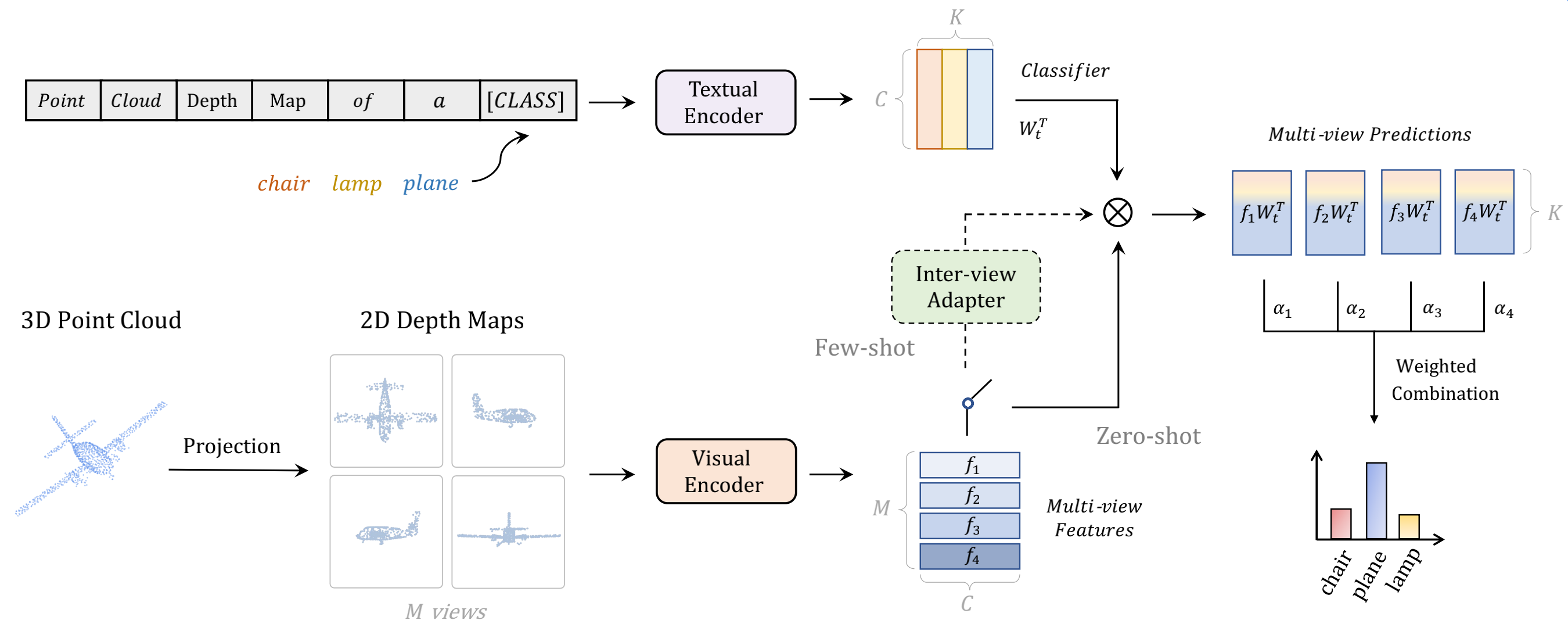
Large-scale pre-trained models have shown promising open-world performance for both vision and language tasks. However, their transferred capacity on 3D point clouds is still limited and only constrained to the classification task. In this paper, we first collaborate CLIP and GPT to be a unified 3D open-world learner, named as PointCLIP V2, which fully unleashes their potential for zero-shot 3D classification, segmentation, and detection. To better align 3D data with the pre-trained language knowledge, PointCLIP V2 contains two key designs. For the visual end, we prompt CLIP via a shape projection module to generate more realistic depth maps, narrowing the domain gap between projected point clouds with natural images. For the textual end, we prompt the GPT model to generate 3D-specific text as the input of CLIP's textual encoder. Without any training in 3D domains, our approach significantly surpasses PointCLIP by +42.90%, +40.44%, and +28.75% accuracy on three datasets for zero-shot 3D classification. On top of that, V2 can be extended to few-shot 3D classification, zero-shot 3D part segmentation, and 3D object detection in a simple manner, demonstrating our generalization ability for unified 3D open-world learning.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract
Tasks
 3D Classification
3D Classification
 3D Object Detection
3D Object Detection
 3D Open-Vocabulary Instance Segmentation
3D Open-Vocabulary Instance Segmentation
 3D Part Segmentation
3D Part Segmentation
 Classification
Descriptive
object-detection
Classification
Descriptive
object-detection
 Object Detection
Object Detection
 Open Vocabulary Object Detection
Training-free 3D Part Segmentation
Training-free 3D Point Cloud Classification
Zero-shot 3D classification
Zero-shot 3D Point Cloud Classification
Zero-Shot Transfer 3D Point Cloud Classification
Open Vocabulary Object Detection
Training-free 3D Part Segmentation
Training-free 3D Point Cloud Classification
Zero-shot 3D classification
Zero-shot 3D Point Cloud Classification
Zero-Shot Transfer 3D Point Cloud Classification
 ShapeNet
ShapeNet
 ScanNet
ScanNet
 ModelNet
ModelNet
 ScanObjectNN
ScanObjectNN
 STPLS3D
STPLS3D

