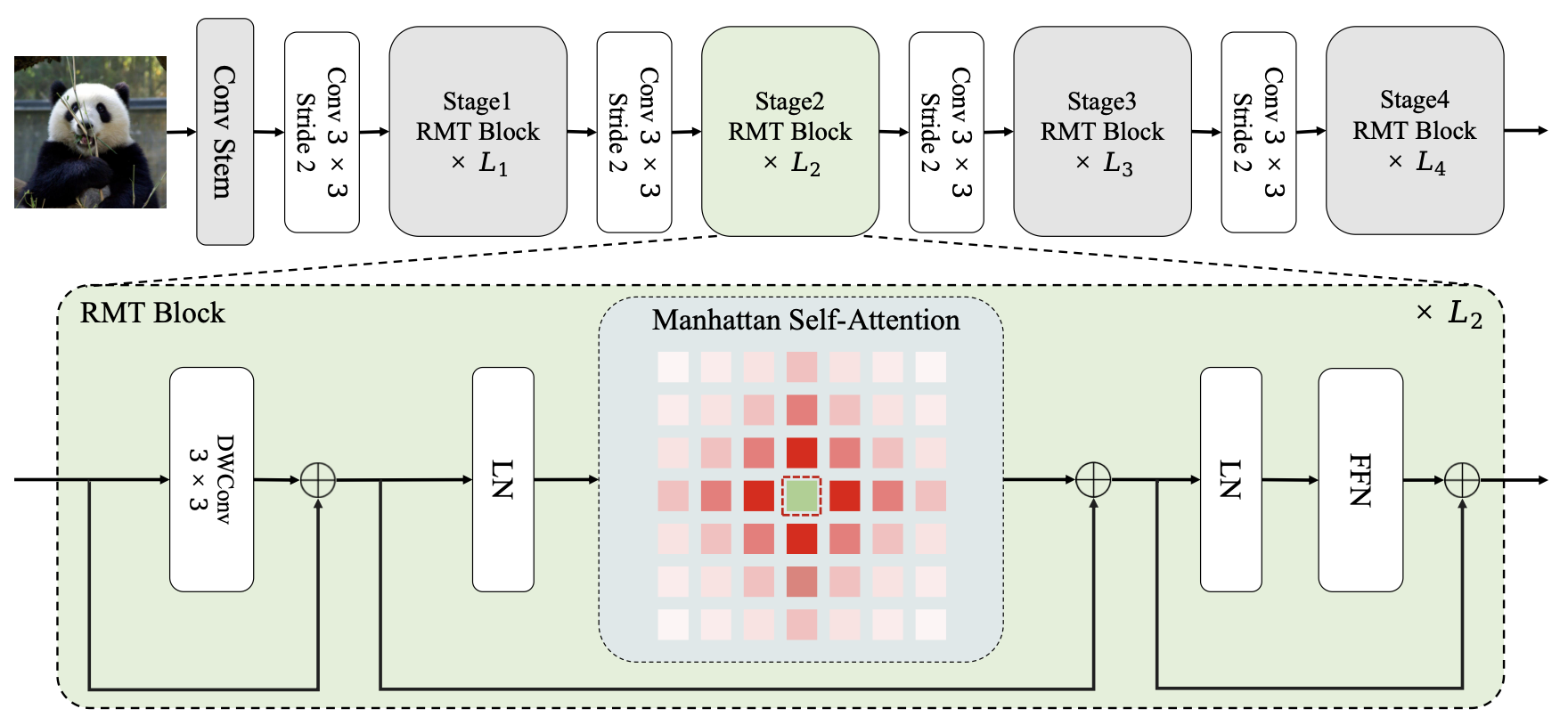
RMT: Retentive Networks Meet Vision Transformers
Vision Transformer (ViT) has gained increasing attention in the computer vision community in recent years. However, the core component of ViT, Self-Attention, lacks explicit spatial priors and bears a quadratic computational complexity, thereby constraining the applicability of ViT. To alleviate these issues, we draw inspiration from the recent Retentive Network (RetNet) in the field of NLP, and propose RMT, a strong vision backbone with explicit spatial prior for general purposes. Specifically, we extend the RetNet's temporal decay mechanism to the spatial domain, and propose a spatial decay matrix based on the Manhattan distance to introduce the explicit spatial prior to Self-Attention. Additionally, an attention decomposition form that adeptly adapts to explicit spatial prior is proposed, aiming to reduce the computational burden of modeling global information without disrupting the spatial decay matrix. Based on the spatial decay matrix and the attention decomposition form, we can flexibly integrate explicit spatial prior into the vision backbone with linear complexity. Extensive experiments demonstrate that RMT exhibits exceptional performance across various vision tasks. Specifically, without extra training data, RMT achieves **84.8%** and **86.1%** top-1 acc on ImageNet-1k with **27M/4.5GFLOPs** and **96M/18.2GFLOPs**. For downstream tasks, RMT achieves **54.5** box AP and **47.2** mask AP on the COCO detection task, and **52.8** mIoU on the ADE20K semantic segmentation task. Code is available at https://github.com/qhfan/RMT
PDF Abstract




 ImageNet
ImageNet
 MS COCO
MS COCO
 ADE20K
ADE20K
