SPEAKER VGG CCT: Cross-corpus Speech Emotion Recognition with Speaker Embedding and Vision Transformers
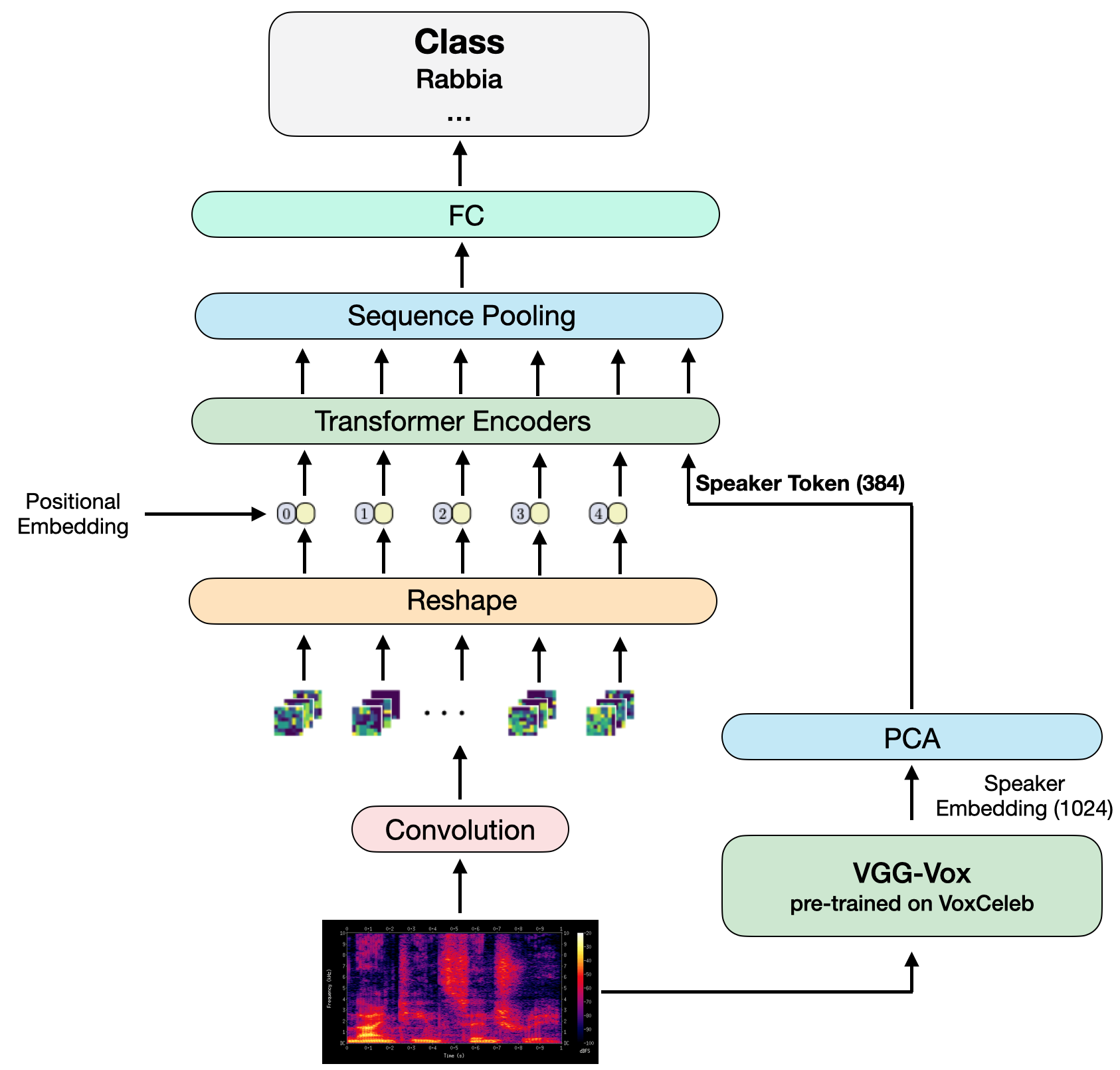
In recent years, Speech Emotion Recognition (SER) has been investigated mainly transforming the speech signal into spectrograms that are then classified using Convolutional Neural Networks pretrained on generic images and fine tuned with spectrograms. In this paper, we start from the general idea above and develop a new learning solution for SER, which is based on Compact Convolutional Transformers (CCTs) combined with a speaker embedding. With CCTs, the learning power of Vision Transformers (ViT) is combined with a diminished need for large volume of data as made possible by the convolution. This is important in SER, where large corpora of data are usually not available. The speaker embedding allows the network to extract an identity representation of the speaker, which is then integrated by means of a self-attention mechanism with the features that the CCT extracts from the spectrogram. Overall, the solution is capable of operating in real-time showing promising results in a cross-corpus scenario, where training and test datasets are kept separate. Experiments have been performed on several benchmarks in a cross-corpus setting as rarely used in the literature, with results that are comparable or superior to those obtained with state-of-the-art network architectures. Our code is available at https://github.com/JabuMlDev/Speaker-VGG-CCT.
PDF Abstract

 IEMOCAP
IEMOCAP
