Video Prediction by Efficient Transformers
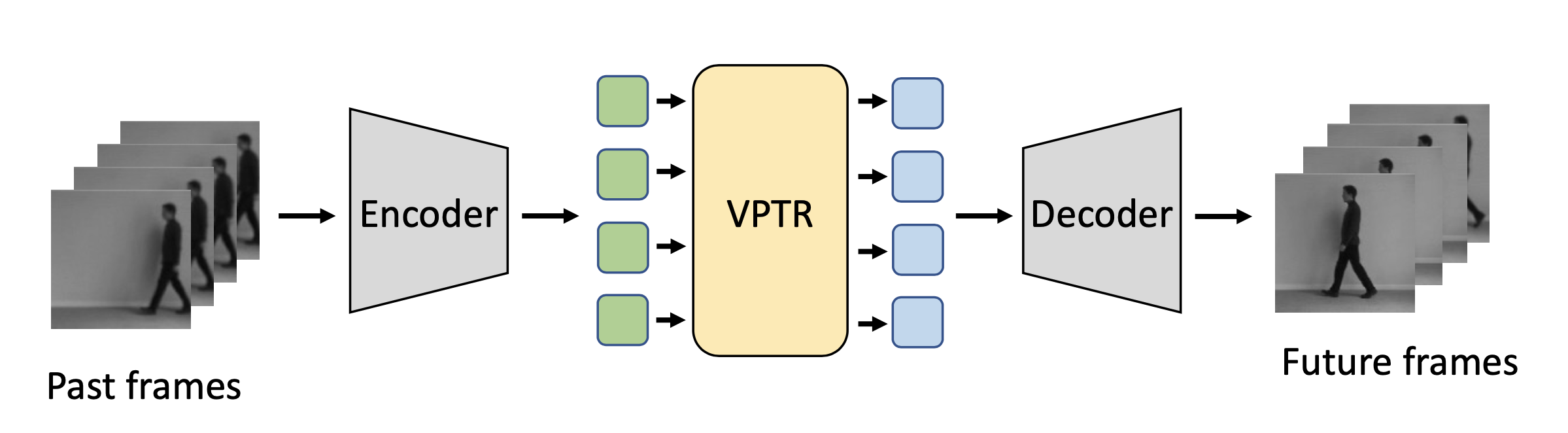
Video prediction is a challenging computer vision task that has a wide range of applications. In this work, we present a new family of Transformer-based models for video prediction. Firstly, an efficient local spatial-temporal separation attention mechanism is proposed to reduce the complexity of standard Transformers. Then, a full autoregressive model, a partial autoregressive model and a non-autoregressive model are developed based on the new efficient Transformer. The partial autoregressive model has a similar performance with the full autoregressive model but a faster inference speed. The non-autoregressive model not only achieves a faster inference speed but also mitigates the quality degradation problem of the autoregressive counterparts, but it requires additional parameters and loss function for learning. Given the same attention mechanism, we conducted a comprehensive study to compare the proposed three video prediction variants. Experiments show that the proposed video prediction models are competitive with more complex state-of-the-art convolutional-LSTM based models. The source code is available at https://github.com/XiYe20/VPTR.
PDF Abstract

 KTH
KTH
 Moving MNIST
Moving MNIST
