Video-TransUNet: Temporally Blended Vision Transformer for CT VFSS Instance Segmentation
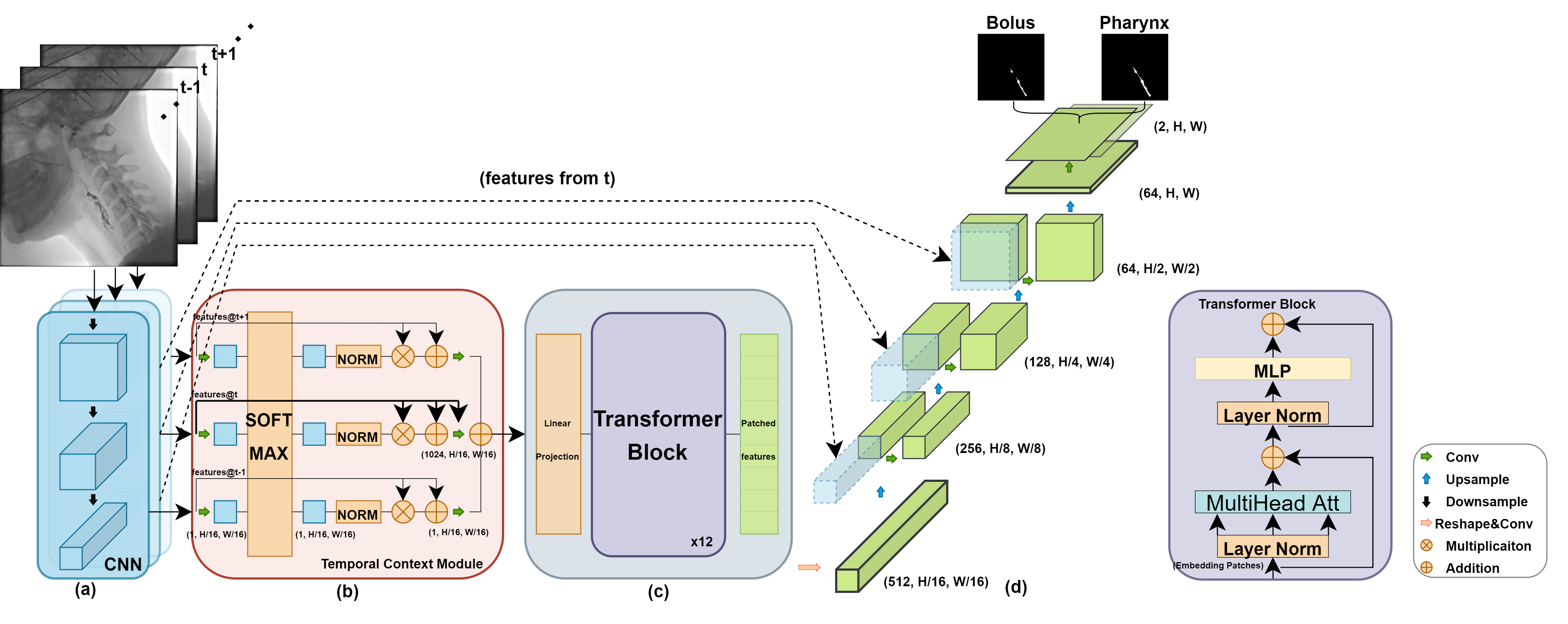
We propose Video-TransUNet, a deep architecture for instance segmentation in medical CT videos constructed by integrating temporal feature blending into the TransUNet deep learning framework. In particular, our approach amalgamates strong frame representation via a ResNet CNN backbone, multi-frame feature blending via a Temporal Context Module (TCM), non-local attention via a Vision Transformer, and reconstructive capabilities for multiple targets via a UNet-based convolutional-deconvolutional architecture with multiple heads. We show that this new network design can significantly outperform other state-of-the-art systems when tested on the segmentation of bolus and pharynx/larynx in Videofluoroscopic Swallowing Study (VFSS) CT sequences. On our VFSS2022 dataset it achieves a dice coefficient of 0.8796 and an average surface distance of 1.0379 pixels. Note that tracking the pharyngeal bolus accurately is a particularly important application in clinical practice since it constitutes the primary method for diagnostics of swallowing impairment. Our findings suggest that the proposed model can indeed enhance the TransUNet architecture via exploiting temporal information and improving segmentation performance by a significant margin. We publish key source code, network weights, and ground truth annotations for simplified performance reproduction.
PDF Abstract



