Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding
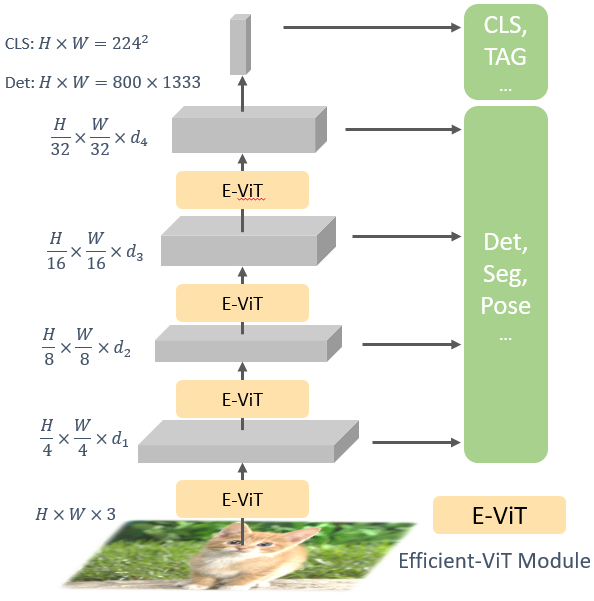
This paper presents a new Vision Transformer (ViT) architecture Multi-Scale Vision Longformer, which significantly enhances the ViT of \cite{dosovitskiy2020image} for encoding high-resolution images using two techniques. The first is the multi-scale model structure, which provides image encodings at multiple scales with manageable computational cost. The second is the attention mechanism of vision Longformer, which is a variant of Longformer \cite{beltagy2020longformer}, originally developed for natural language processing, and achieves a linear complexity w.r.t. the number of input tokens. A comprehensive empirical study shows that the new ViT significantly outperforms several strong baselines, including the existing ViT models and their ResNet counterparts, and the Pyramid Vision Transformer from a concurrent work \cite{wang2021pyramid}, on a range of vision tasks, including image classification, object detection, and segmentation. The models and source code are released at \url{https://github.com/microsoft/vision-longformer}.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract




 ImageNet
ImageNet
 MS COCO
MS COCO

