DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
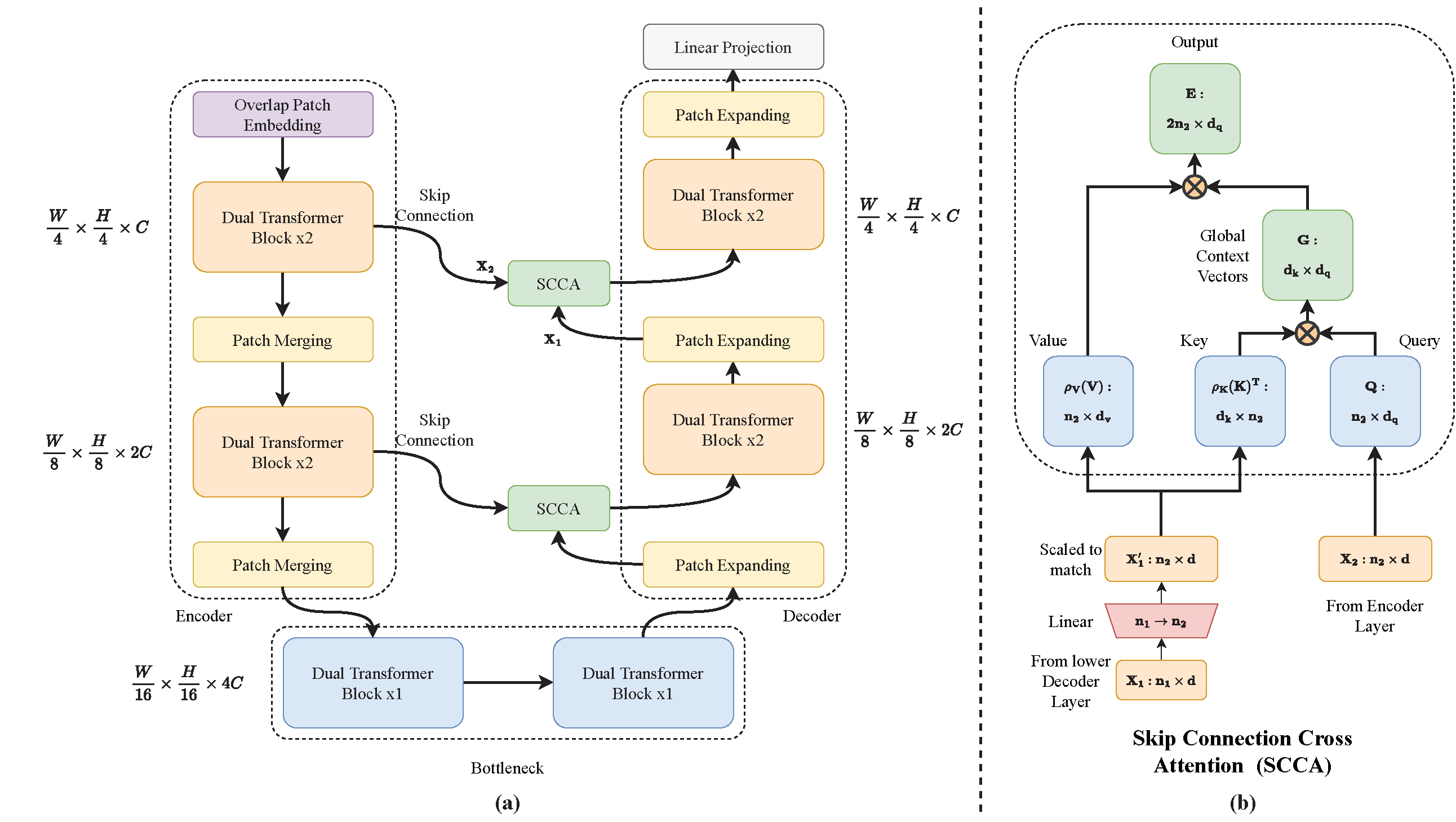
Transformers have recently gained attention in the computer vision domain due to their ability to model long-range dependencies. However, the self-attention mechanism, which is the core part of the Transformer model, usually suffers from quadratic computational complexity with respect to the number of tokens. Many architectures attempt to reduce model complexity by limiting the self-attention mechanism to local regions or by redesigning the tokenization process. In this paper, we propose DAE-Former, a novel method that seeks to provide an alternative perspective by efficiently designing the self-attention mechanism. More specifically, we reformulate the self-attention mechanism to capture both spatial and channel relations across the whole feature dimension while staying computationally efficient. Furthermore, we redesign the skip connection path by including the cross-attention module to ensure the feature reusability and enhance the localization power. Our method outperforms state-of-the-art methods on multi-organ cardiac and skin lesion segmentation datasets without requiring pre-training weights. The code is publicly available at https://github.com/mindflow-institue/DAEFormer.
PDF Abstract




