On the Connection between Local Attention and Dynamic Depth-wise Convolution
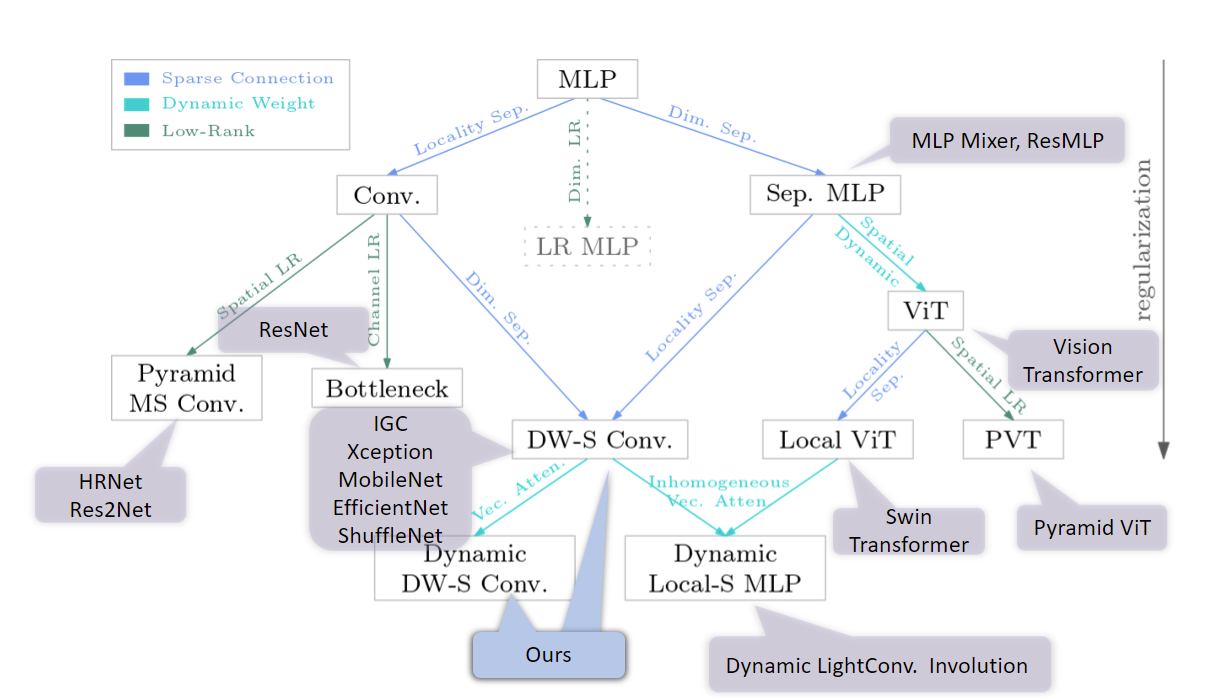
Vision Transformer (ViT) attains state-of-the-art performance in visual recognition, and the variant, Local Vision Transformer, makes further improvements. The major component in Local Vision Transformer, local attention, performs the attention separately over small local windows. We rephrase local attention as a channel-wise locally-connected layer and analyze it from two network regularization manners, sparse connectivity and weight sharing, as well as weight computation. Sparse connectivity: there is no connection across channels, and each position is connected to the positions within a small local window. Weight sharing: the connection weights for one position are shared across channels or within each group of channels. Dynamic weight: the connection weights are dynamically predicted according to each image instance. We point out that local attention resembles depth-wise convolution and its dynamic version in sparse connectivity. The main difference lies in weight sharing - depth-wise convolution shares connection weights (kernel weights) across spatial positions. We empirically observe that the models based on depth-wise convolution and the dynamic variant with lower computation complexity perform on-par with or sometimes slightly better than Swin Transformer, an instance of Local Vision Transformer, for ImageNet classification, COCO object detection and ADE semantic segmentation. These observations suggest that Local Vision Transformer takes advantage of two regularization forms and dynamic weight to increase the network capacity. Code is available at https://github.com/Atten4Vis/DemystifyLocalViT.
PDF Abstract ICLR 2022 PDF ICLR 2022 Abstract



 ImageNet
ImageNet
 MS COCO
MS COCO
 ADE20K
ADE20K
