Going Full-TILT Boogie on Document Understanding with Text-Image-Layout Transformer
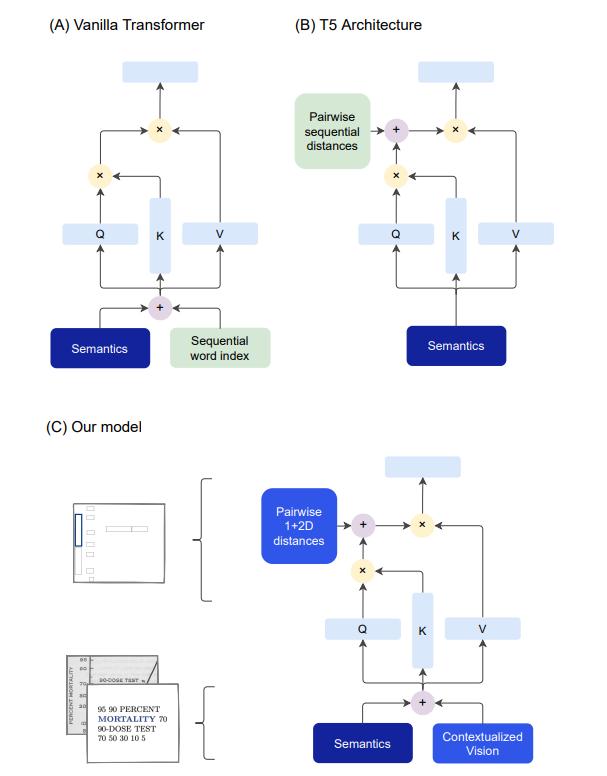
We address the challenging problem of Natural Language Comprehension beyond plain-text documents by introducing the TILT neural network architecture which simultaneously learns layout information, visual features, and textual semantics. Contrary to previous approaches, we rely on a decoder capable of unifying a variety of problems involving natural language. The layout is represented as an attention bias and complemented with contextualized visual information, while the core of our model is a pretrained encoder-decoder Transformer. Our novel approach achieves state-of-the-art results in extracting information from documents and answering questions which demand layout understanding (DocVQA, CORD, SROIE). At the same time, we simplify the process by employing an end-to-end model.
PDF AbstractCode




 SQuAD
SQuAD
 Natural Questions
Natural Questions
 RACE
RACE
 DROP
DROP
 CoQA
CoQA
 TextVQA
TextVQA
 QuAC
QuAC
 TyDiQA
TyDiQA
 FUNSD
FUNSD
 QASC
QASC
 RVL-CDIP
RVL-CDIP
 SROIE
SROIE
 WikiTableQuestions
WikiTableQuestions
 DVQA
DVQA
 InfographicVQA
InfographicVQA
 WikiReading
WikiReading
Results from the Paper
 Ranked #7 on
Visual Question Answering (VQA)
on InfographicVQA
(using extra training data)
Ranked #7 on
Visual Question Answering (VQA)
on InfographicVQA
(using extra training data)
