| TASK |
DATASET |
MODEL |
METRIC NAME |
METRIC VALUE |
GLOBAL RANK |
REMOVE |
|
Semantic Segmentation
|
ADE20K
|
Mask2Former(Swin-B)
|
Validation mIoU
|
55.1
|
# 44
|
|
|
Semantic Segmentation
|
ADE20K
|
Mask2Former (SwinL)
|
Validation mIoU
|
57.3
|
# 27
|
|
|
Semantic Segmentation
|
ADE20K
|
Mask2Former (SwinL-FaPN)
|
Validation mIoU
|
57.7
|
# 21
|
|
|
Semantic Segmentation
|
ADE20K
|
Mask2Former (Swin-L-FaPN)
|
Validation mIoU
|
56.4
|
# 34
|
|
|
Panoptic Segmentation
|
ADE20K val
|
Mask2Former (Swin-L)
|
PQ
|
48.1
|
# 15
|
|
|
Panoptic Segmentation
|
ADE20K val
|
Mask2Former (Swin-L)
|
AP
|
34.2
|
# 11
|
|
|
Panoptic Segmentation
|
ADE20K val
|
Mask2Former (Swin-L)
|
mIoU
|
54.5
|
# 15
|
|
|
Semantic Segmentation
|
ADE20K val
|
Mask2Former (Swin-L-FaPN)
|
mIoU
|
56.4
|
# 23
|
|
|
Panoptic Segmentation
|
ADE20K val
|
Mask2Former (ResNet-50, 640x640)
|
AP
|
26.5
|
# 13
|
|
|
Panoptic Segmentation
|
ADE20K val
|
Mask2Former (ResNet-50, 640x640)
|
mIoU
|
46.1
|
# 17
|
|
|
Panoptic Segmentation
|
ADE20K val
|
Mask2Former (ResNet-50, 640x640)
|
PQ
|
39.7
|
# 19
|
|
|
Panoptic Segmentation
|
ADE20K val
|
Mask2Former (Swin-L + FAPN, 640x640)
|
PQ
|
46.2
|
# 16
|
|
|
Panoptic Segmentation
|
ADE20K val
|
Mask2Former (Swin-L + FAPN, 640x640)
|
AP
|
33.2
|
# 12
|
|
|
Panoptic Segmentation
|
ADE20K val
|
Mask2Former (Swin-L + FAPN, 640x640)
|
mIoU
|
55.4
|
# 12
|
|
|
Instance Segmentation
|
ADE20K val
|
Mask2Former (Swin-L, single-scale)
|
AP
|
34.9
|
# 9
|
|
|
Instance Segmentation
|
ADE20K val
|
Mask2Former (Swin-L, single-scale)
|
APS
|
16.3
|
# 4
|
|
|
Instance Segmentation
|
ADE20K val
|
Mask2Former (Swin-L, single-scale)
|
APM
|
40
|
# 4
|
|
|
Instance Segmentation
|
ADE20K val
|
Mask2Former (Swin-L, single-scale)
|
APL
|
54.7
|
# 5
|
|
|
Panoptic Segmentation
|
ADE20K val
|
Panoptic-DeepLab (SwideRNet)
|
PQ
|
37.9
|
# 20
|
|
|
Panoptic Segmentation
|
ADE20K val
|
Panoptic-DeepLab (SwideRNet)
|
mIoU
|
50
|
# 16
|
|
|
Instance Segmentation
|
ADE20K val
|
Mask2Former (ResNet-50)
|
APM
|
28.9
|
# 7
|
|
|
Instance Segmentation
|
ADE20K val
|
Mask2Former (ResNet-50)
|
APL
|
43.1
|
# 7
|
|
|
Instance Segmentation
|
ADE20K val
|
Mask2Former (Swin-L + FAPN)
|
AP
|
33.4
|
# 10
|
|
|
Instance Segmentation
|
ADE20K val
|
Mask2Former (Swin-L + FAPN)
|
APS
|
14.6
|
# 6
|
|
|
Instance Segmentation
|
ADE20K val
|
Mask2Former (Swin-L + FAPN)
|
APM
|
37.6
|
# 6
|
|
|
Instance Segmentation
|
ADE20K val
|
Mask2Former (Swin-L + FAPN)
|
APL
|
54.6
|
# 6
|
|
|
Instance Segmentation
|
ADE20K val
|
Mask2Former (ResNet50)
|
AP
|
26.4
|
# 11
|
|
|
Instance Segmentation
|
ADE20K val
|
Mask2Former (ResNet50)
|
APS
|
10.4
|
# 7
|
|
|
Semantic Segmentation
|
ADE20K val
|
Mask2Former (Swin-L-FaPN, multiscale)
|
mIoU
|
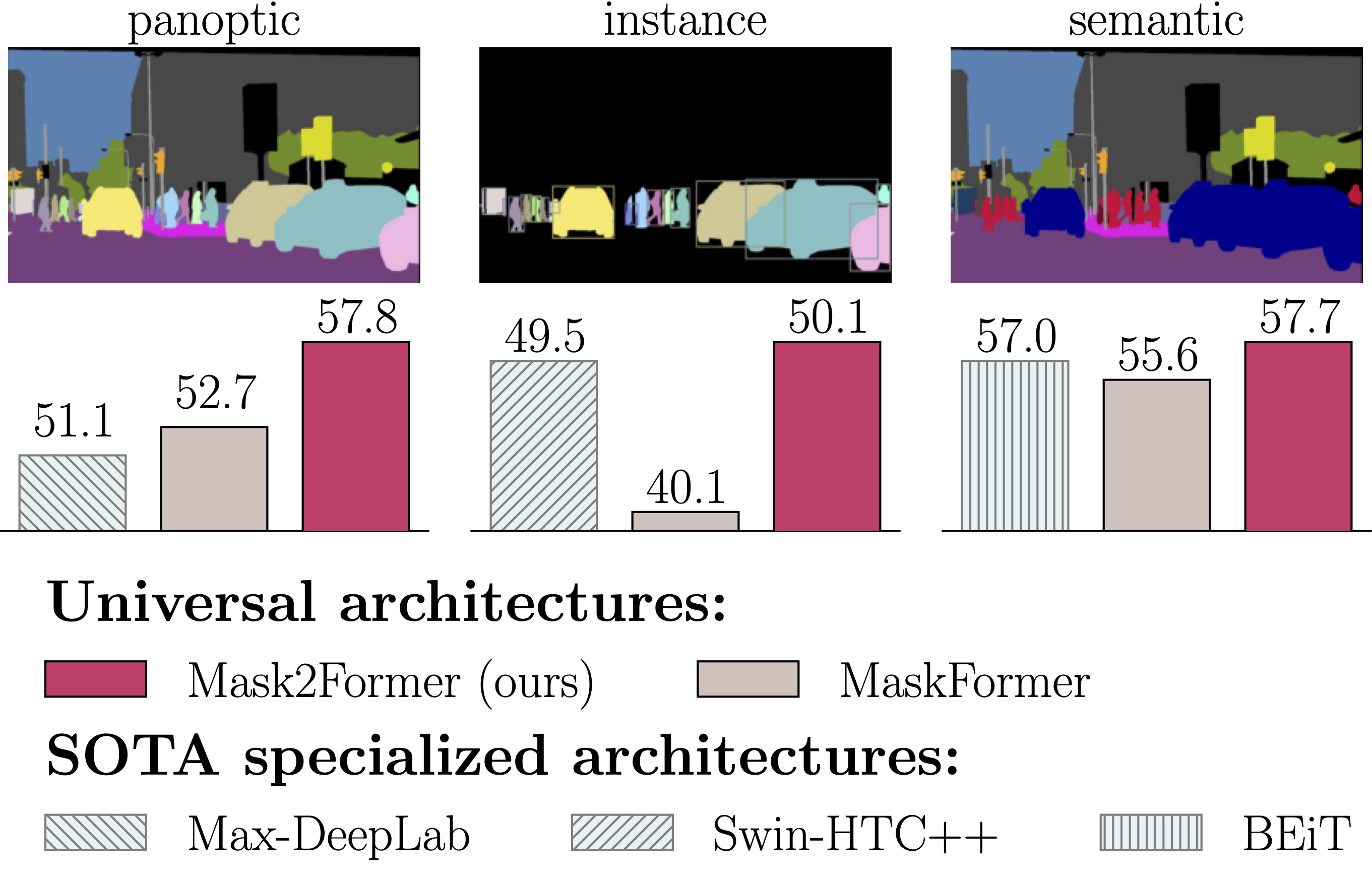
57.7
|
# 16
|
|
|
Instance Segmentation
|
Cityscapes val
|
Mask2Former (Swin-L, single-scale)
|
mask AP
|
43.7
|
# 9
|
|
|
Semantic Segmentation
|
Cityscapes val
|
Mask2Former (Swin-L)
|
mIoU
|
84.3
|
# 16
|
|
|
Panoptic Segmentation
|
Cityscapes val
|
Mask2Former (Swin-L)
|
PQ
|
66.6
|
# 14
|
|
|
Panoptic Segmentation
|
Cityscapes val
|
Mask2Former (Swin-L)
|
mIoU
|
82.9
|
# 13
|
|
|
Panoptic Segmentation
|
Cityscapes val
|
Mask2Former (Swin-L)
|
AP
|
43.6
|
# 12
|
|
|
Instance Segmentation
|
Cityscapes val
|
Mask2Former (Swin-B)
|
mask AP
|
42
|
# 10
|
|
|
Instance Segmentation
|
Cityscapes val
|
Mask2Former (Swin-S)
|
mask AP
|
41.8
|
# 11
|
|
|
Instance Segmentation
|
Cityscapes val
|
Mask2Former (Swin-T)
|
mask AP
|
39.7
|
# 13
|
|
|
Instance Segmentation
|
Cityscapes val
|
Mask2Former (ResNet-101)
|
mask AP
|
38.5
|
# 14
|
|
|
Instance Segmentation
|
Cityscapes val
|
Mask2Former (ResNet-50)
|
mask AP
|
37.4
|
# 15
|
|
|
Panoptic Segmentation
|
COCO minival
|
Mask2Former (single-scale)
|
PQ
|
57.8
|
# 14
|
|
|
Panoptic Segmentation
|
COCO minival
|
Mask2Former (single-scale)
|
PQth
|
64.2
|
# 8
|
|
|
Panoptic Segmentation
|
COCO minival
|
Mask2Former (single-scale)
|
PQst
|
48.1
|
# 9
|
|
|
Panoptic Segmentation
|
COCO minival
|
Mask2Former (single-scale)
|
AP
|
48.6
|
# 8
|
|
|
Instance Segmentation
|
COCO minival
|
Mask2Former (Swin-L)
|
mask AP
|
50.1
|
# 24
|
|
|
Instance Segmentation
|
COCO test-dev
|
Mask2Former (Swin-L, single scale)
|
mask AP
|
50.5
|
# 19
|
|
|
Instance Segmentation
|
COCO test-dev
|
Mask2Former (Swin-L, single scale)
|
AP50
|
74.9
|
# 6
|
|
|
Instance Segmentation
|
COCO test-dev
|
Mask2Former (Swin-L, single scale)
|
AP75
|
54.9
|
# 5
|
|
|
Instance Segmentation
|
COCO test-dev
|
Mask2Former (Swin-L, single scale)
|
APS
|
29.1
|
# 10
|
|
|
Instance Segmentation
|
COCO test-dev
|
Mask2Former (Swin-L, single scale)
|
APM
|
53.8
|
# 5
|
|
|
Instance Segmentation
|
COCO test-dev
|
Mask2Former (Swin-L, single scale)
|
APL
|
71.2
|
# 2
|
|
|
Panoptic Segmentation
|
COCO test-dev
|
Mask2Former (Swin-L)
|
PQ
|
58.3
|
# 3
|
|
|
Panoptic Segmentation
|
COCO test-dev
|
Mask2Former (Swin-L)
|
PQst
|
48.1
|
# 3
|
|
|
Panoptic Segmentation
|
COCO test-dev
|
Mask2Former (Swin-L)
|
PQth
|
65.1
|
# 1
|
|
|
Instance Segmentation
|
COCO val (panoptic labels)
|
Mask2Former (Swin-L, single-scale)
|
AP
|
49.1
|
# 3
|
|
|
Semantic Segmentation
|
Mapillary val
|
Mask2Former (Swin-L, multiscale)
|
mIoU
|
64.7
|
# 3
|
|
|
Semantic Segmentation
|
MS COCO
|
MaskFormer (Swin-L, single-scale)
|
mIoU
|
64.8
|
# 5
|
|
|
Semantic Segmentation
|
MS COCO
|
Mask2Former (Swin-L, single-scale)
|
mIoU
|
67.4
|
# 3
|
|
 Colab
Colab
 Spaces
Spaces
 Replicate
Replicate





 MS COCO
MS COCO
 Cityscapes
Cityscapes
 ADE20K
ADE20K
 Mapillary Vistas Dataset
Mapillary Vistas Dataset

