Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
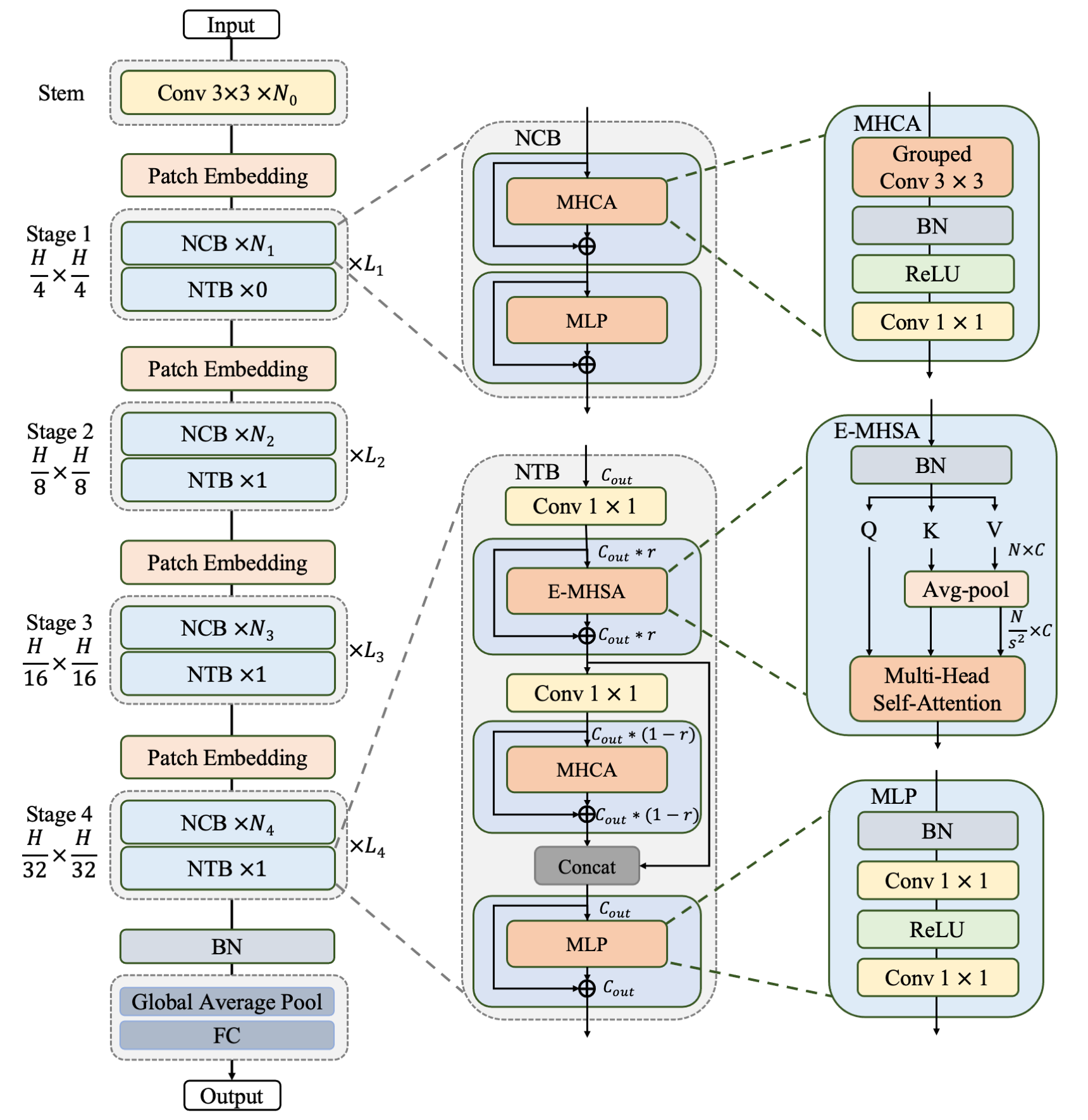
Due to the complex attention mechanisms and model design, most existing vision Transformers (ViTs) can not perform as efficiently as convolutional neural networks (CNNs) in realistic industrial deployment scenarios, e.g. TensorRT and CoreML. This poses a distinct challenge: Can a visual neural network be designed to infer as fast as CNNs and perform as powerful as ViTs? Recent works have tried to design CNN-Transformer hybrid architectures to address this issue, yet the overall performance of these works is far away from satisfactory. To end these, we propose a next generation vision Transformer for efficient deployment in realistic industrial scenarios, namely Next-ViT, which dominates both CNNs and ViTs from the perspective of latency/accuracy trade-off. In this work, the Next Convolution Block (NCB) and Next Transformer Block (NTB) are respectively developed to capture local and global information with deployment-friendly mechanisms. Then, Next Hybrid Strategy (NHS) is designed to stack NCB and NTB in an efficient hybrid paradigm, which boosts performance in various downstream tasks. Extensive experiments show that Next-ViT significantly outperforms existing CNNs, ViTs and CNN-Transformer hybrid architectures with respect to the latency/accuracy trade-off across various vision tasks. On TensorRT, Next-ViT surpasses ResNet by 5.5 mAP (from 40.4 to 45.9) on COCO detection and 7.7% mIoU (from 38.8% to 46.5%) on ADE20K segmentation under similar latency. Meanwhile, it achieves comparable performance with CSWin, while the inference speed is accelerated by 3.6x. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.1% to 48.6%) on ADE20K segmentation under similar latency. Our code and models are made public at: https://github.com/bytedance/Next-ViT
PDF Abstract


 ImageNet
ImageNet
 MS COCO
MS COCO
 ADE20K
ADE20K

