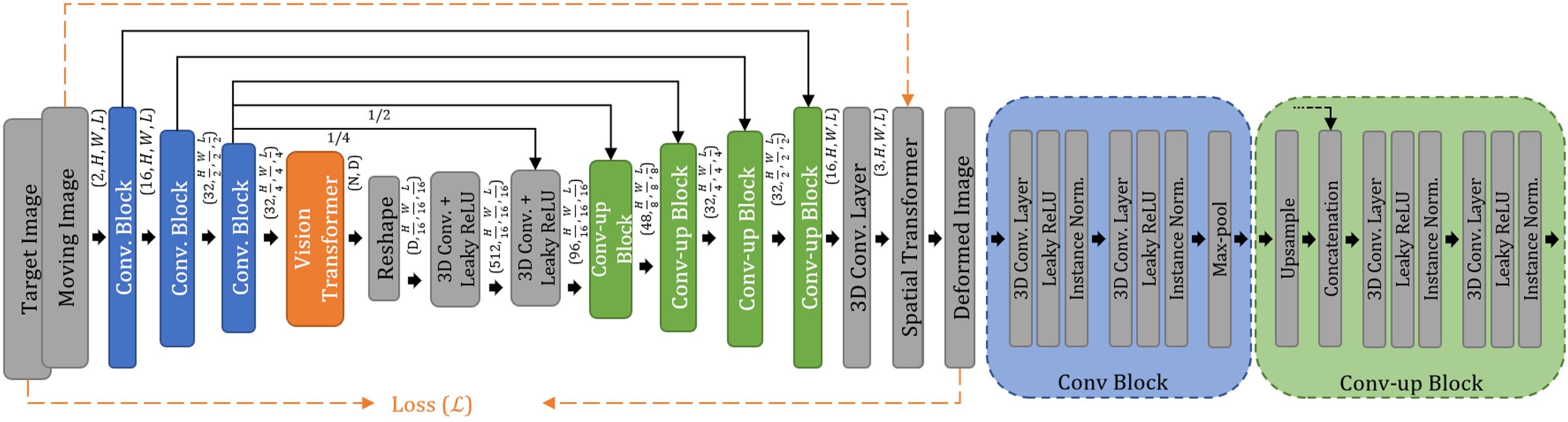
ViT-V-Net: Vision Transformer for Unsupervised Volumetric Medical Image Registration
In the last decade, convolutional neural networks (ConvNets) have dominated and achieved state-of-the-art performances in a variety of medical imaging applications. However, the performances of ConvNets are still limited by lacking the understanding of long-range spatial relations in an image. The recently proposed Vision Transformer (ViT) for image classification uses a purely self-attention-based model that learns long-range spatial relations to focus on the relevant parts of an image. Nevertheless, ViT emphasizes the low-resolution features because of the consecutive downsamplings, result in a lack of detailed localization information, making it unsuitable for image registration. Recently, several ViT-based image segmentation methods have been combined with ConvNets to improve the recovery of detailed localization information. Inspired by them, we present ViT-V-Net, which bridges ViT and ConvNet to provide volumetric medical image registration. The experimental results presented here demonstrate that the proposed architecture achieves superior performance to several top-performing registration methods.
PDF Abstract




 IXI
IXI

