VL-BERT: Pre-training of Generic Visual-Linguistic Representations
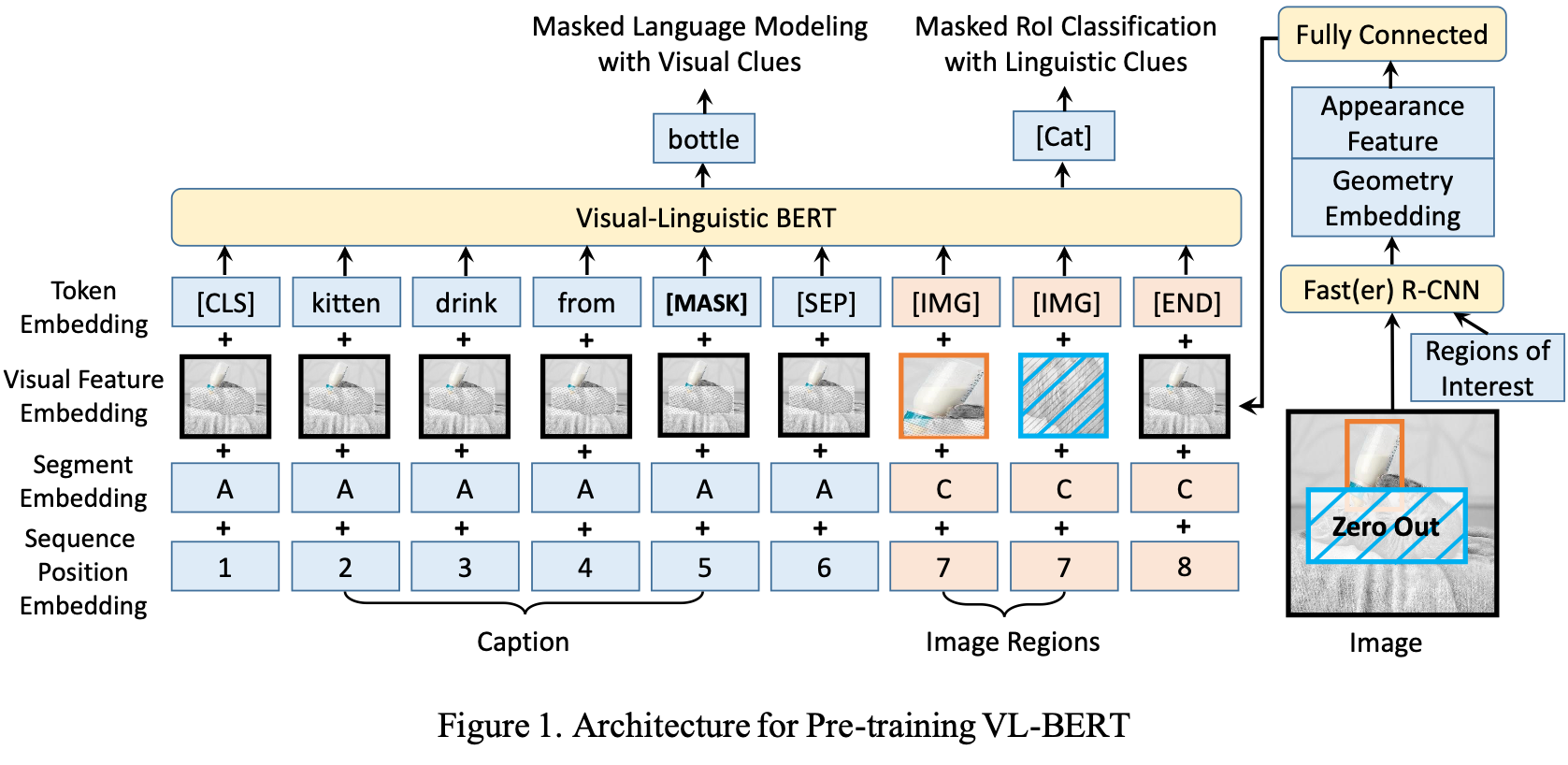
We introduce a new pre-trainable generic representation for visual-linguistic tasks, called Visual-Linguistic BERT (VL-BERT for short). VL-BERT adopts the simple yet powerful Transformer model as the backbone, and extends it to take both visual and linguistic embedded features as input. In it, each element of the input is either of a word from the input sentence, or a region-of-interest (RoI) from the input image. It is designed to fit for most of the visual-linguistic downstream tasks. To better exploit the generic representation, we pre-train VL-BERT on the massive-scale Conceptual Captions dataset, together with text-only corpus. Extensive empirical analysis demonstrates that the pre-training procedure can better align the visual-linguistic clues and benefit the downstream tasks, such as visual commonsense reasoning, visual question answering and referring expression comprehension. It is worth noting that VL-BERT achieved the first place of single model on the leaderboard of the VCR benchmark. Code is released at \url{https://github.com/jackroos/VL-BERT}.
PDF Abstract ICLR 2020 PDF ICLR 2020 Abstract





 ImageNet
ImageNet
 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 Visual Genome
Visual Genome
 Visual Question Answering v2.0
Visual Question Answering v2.0
 Conceptual Captions
Conceptual Captions
 RefCOCO
RefCOCO
 VCR
VCR
 Talk2Car
Talk2Car

