Datasets for Large Language Models: A Comprehensive Survey
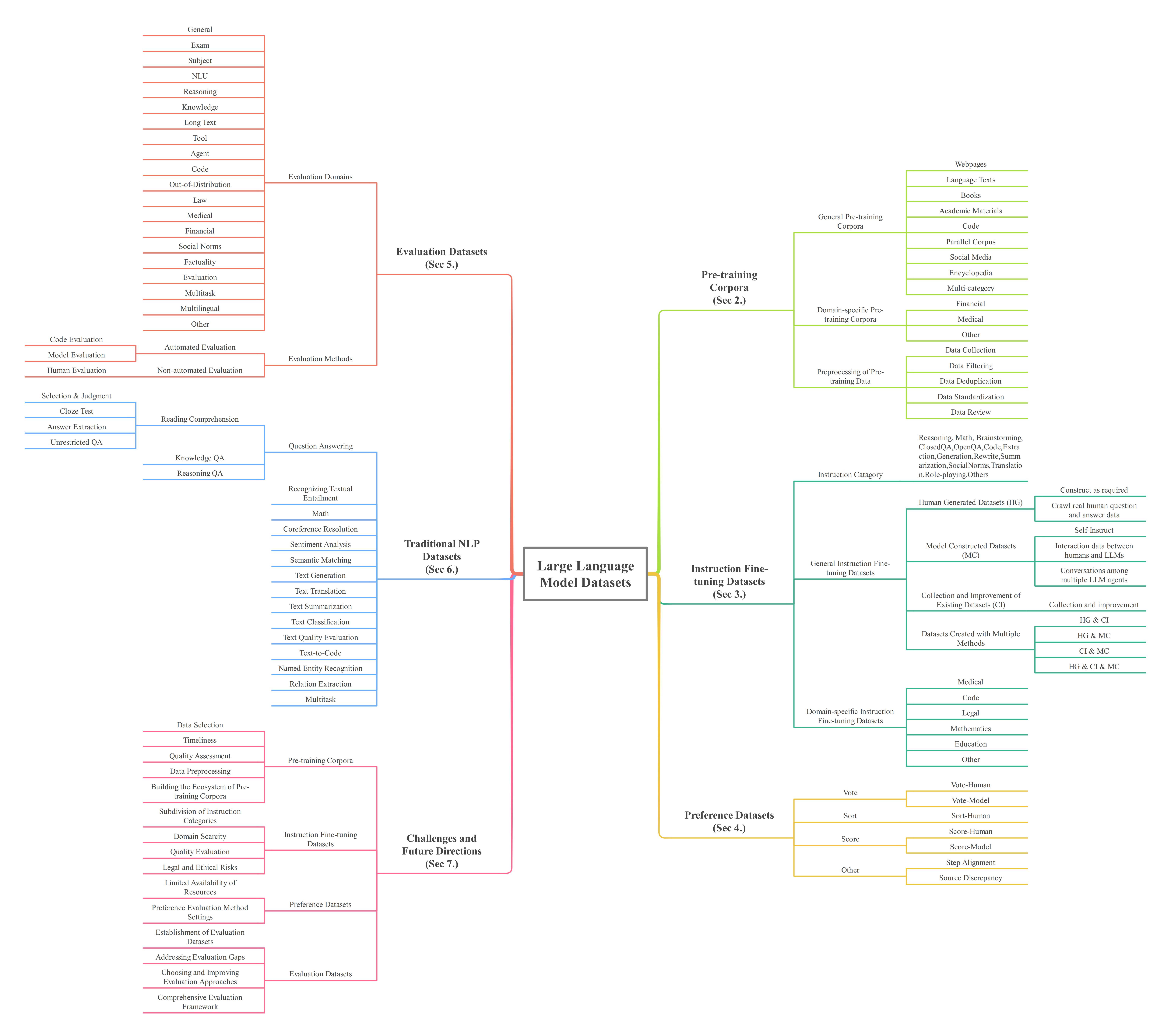
This paper embarks on an exploration into the Large Language Model (LLM) datasets, which play a crucial role in the remarkable advancements of LLMs. The datasets serve as the foundational infrastructure analogous to a root system that sustains and nurtures the development of LLMs. Consequently, examination of these datasets emerges as a critical topic in research. In order to address the current lack of a comprehensive overview and thorough analysis of LLM datasets, and to gain insights into their current status and future trends, this survey consolidates and categorizes the fundamental aspects of LLM datasets from five perspectives: (1) Pre-training Corpora; (2) Instruction Fine-tuning Datasets; (3) Preference Datasets; (4) Evaluation Datasets; (5) Traditional Natural Language Processing (NLP) Datasets. The survey sheds light on the prevailing challenges and points out potential avenues for future investigation. Additionally, a comprehensive review of the existing available dataset resources is also provided, including statistics from 444 datasets, covering 8 language categories and spanning 32 domains. Information from 20 dimensions is incorporated into the dataset statistics. The total data size surveyed surpasses 774.5 TB for pre-training corpora and 700M instances for other datasets. We aim to present the entire landscape of LLM text datasets, serving as a comprehensive reference for researchers in this field and contributing to future studies. Related resources are available at: https://github.com/lmmlzn/Awesome-LLMs-Datasets.
PDF Abstract


Datasets
 GLUE
GLUE
 SST
SST
 SQuAD
SQuAD
 MultiNLI
MultiNLI
 IMDb Movie Reviews
SST-2
IMDb Movie Reviews
SST-2
 SNLI
SNLI
 Natural Questions
Natural Questions
 MS MARCO
MS MARCO
 AG News
AG News
 MMLU
MMLU
 MRPC
MRPC
 GSM8K
GSM8K
 C4
CoNLL 2003
C4
CoNLL 2003
 TriviaQA
TriviaQA
 CoLA
CoLA
 HotpotQA
HotpotQA
 HumanEval
HumanEval
 HellaSwag
HellaSwag
 BoolQ
BoolQ
 MATH
MATH
 SuperGLUE
SuperGLUE
 PIQA
PIQA
 RACE
RACE
 OpenBookQA
OpenBookQA
 CommonsenseQA
CommonsenseQA
 WinoGrande
WinoGrande
 XNLI
XNLI
 WebText
WebText
 BookCorpus
BookCorpus
 The Pile
The Pile
 WSC
WSC
 DROP
DROP
 COPA
COPA
 TruthfulQA
TruthfulQA
 ANLI
MBPP
ANLI
MBPP
 CoQA
CoQA
 BIG-bench
BIG-bench
 SVAMP
SVAMP
 WikiQA
WikiQA
 TACRED
TACRED
 LAMBADA
LAMBADA
 StrategyQA
StrategyQA
 FewRel
WiC
FewRel
WiC
 QuAC
QuAC
 CodeXGLUE
CodeXGLUE
 PAWS-X
MT-Bench
PAWS-X
MT-Bench
 SentEval
BBH
SentEval
BBH
 PAWS
PAWS
 PubMedQA
PubMedQA
 DocRED
DocRED
 WebNLG
WebNLG
 MultiRC
MultiRC
 ScienceQA
ScienceQA
 S2ORC
OpenWebText
mC4
S2ORC
OpenWebText
mC4
 MCTest
SAMSum
MCTest
SAMSum
 WikiHow
CrowS-Pairs
WikiHow
CrowS-Pairs
 Multi-News
Multi-News
 APPS
APPS
 NEWSROOM
HELM
NEWSROOM
HELM
 QASC
QASC
 ReCoRD
ASDiv
CC100
CLUE
ReCoRD
ASDiv
CC100
CLUE
 MathQA
CommonGen
Math23K
MathQA
CommonGen
Math23K
 CosmosQA
PG-19
CosmosQA
PG-19
 SciQ
SciQ
 RealNews
RealNews
 ReClor
ReClor
 The Stack
The Stack
 LogiQA
LogiQA
 DREAM
DREAM
 CMRC
CMRC
 DuReader
DuReader
 LCSTS
ParaCrawl
LCSTS
ParaCrawl
 QASPER
QASPER
 Weibo NER
Weibo NER
 WikiLingua
WikiLingua
 Quoref
CMRC 2018
Natural Instructions
Quoref
CMRC 2018
Natural Instructions
 XL-Sum
XL-Sum
 DuoRC
C3
DuoRC
C3
 OCNLI
AQUA-RAT
OCNLI
AQUA-RAT
 ToolBench
ToolBench
 ECQA
ECQA
 LexGLUE
LexGLUE
 ChID
ChID
 DS-1000
CMNLI
DS-1000
CMNLI
 xP3
MARC
xP3
MARC
 decaNLP
decaNLP
 CUAD
HaluEval
CUAD
HaluEval
 QuaRTz
QuaRTz
 MiniF2F
Pushshift Reddit
MiniF2F
Pushshift Reddit
 AdversarialQA
AdversarialQA
 ROPES
ROPES
 CREAK
AgentBench
CREAK
AgentBench
 WIQA
WIQA
 HeadQA
HeadQA
 QuaRel
QuaRel
 CLOTH
AESLC
CLOTH
AESLC
 RAFT
RAFT
 PRM800K
PRM800K
 SciBench
SciBench
 QED
LCCC
PsyQA
QED
LCCC
PsyQA
 M3KE
M3KE
 ProsocialDialog
M3Exam
ProsocialDialog
M3Exam
 FewCLUE
FewCLUE
 Lila
LegalBench
EPRSTMT
CValues
HumanEvalPack
Lila
LegalBench
EPRSTMT
CValues
HumanEvalPack
 WanJuan
MMCU
WinoWhy
JEC-QA
WanJuan
MMCU
WinoWhy
JEC-QA
 CC-Stories
CC-Stories
 PROST
PROST
 Open-Platypus
CMB
CMRC 2019
GLUE-X
Open-Platypus
CMB
CMRC 2019
GLUE-X
 NaturalProofs
SafetyBench
CommitPack
NaturalProofs
SafetyBench
CommitPack
 DialogStudio
CommitPackFT
CLUECorpus2020
CUGE
YACLC
CG-Eval
SuperCLUE
DialogStudio
CommitPackFT
CLUECorpus2020
CUGE
YACLC
CG-Eval
SuperCLUE
 CSCD-IME
CSCD-IME
