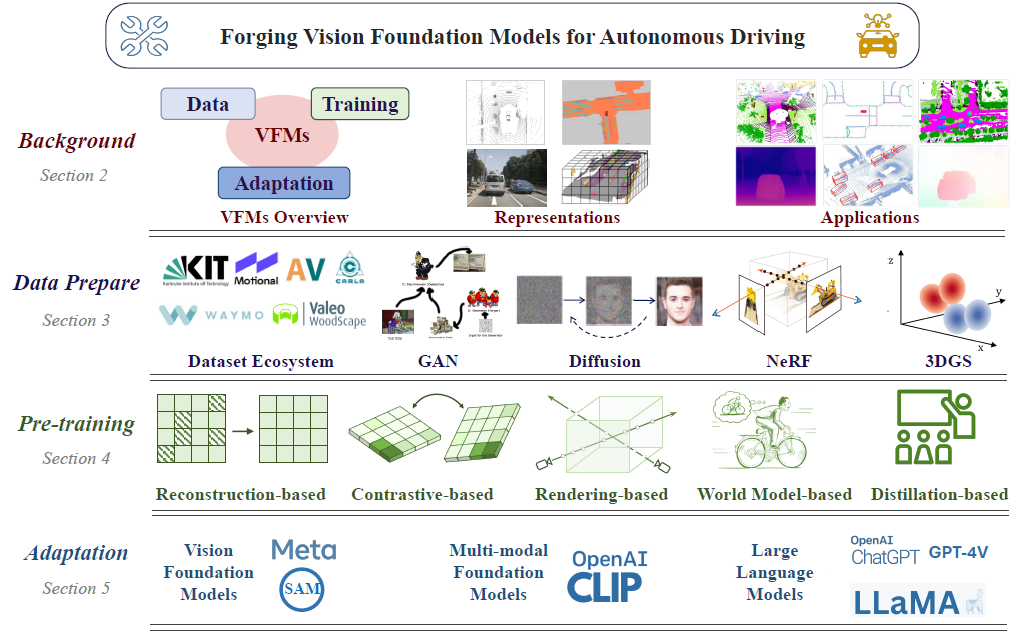
Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities
The rise of large foundation models, trained on extensive datasets, is revolutionizing the field of AI. Models such as SAM, DALL-E2, and GPT-4 showcase their adaptability by extracting intricate patterns and performing effectively across diverse tasks, thereby serving as potent building blocks for a wide range of AI applications. Autonomous driving, a vibrant front in AI applications, remains challenged by the lack of dedicated vision foundation models (VFMs). The scarcity of comprehensive training data, the need for multi-sensor integration, and the diverse task-specific architectures pose significant obstacles to the development of VFMs in this field. This paper delves into the critical challenge of forging VFMs tailored specifically for autonomous driving, while also outlining future directions. Through a systematic analysis of over 250 papers, we dissect essential techniques for VFM development, including data preparation, pre-training strategies, and downstream task adaptation. Moreover, we explore key advancements such as NeRF, diffusion models, 3D Gaussian Splatting, and world models, presenting a comprehensive roadmap for future research. To empower researchers, we have built and maintained https://github.com/zhanghm1995/Forge_VFM4AD, an open-access repository constantly updated with the latest advancements in forging VFMs for autonomous driving.
PDF Abstract
 Cityscapes
Cityscapes
 KITTI
KITTI
 nuScenes
nuScenes
 CARLA
CARLA
 SemanticKITTI
SemanticKITTI
 BDD100K
BDD100K
 Argoverse
Argoverse
 KITTI-360
KITTI-360
 Argoverse 2
Argoverse 2
 IDD
IDD
 ONCE
ONCE
 PandaSet
PandaSet
 BDD-X
BDD-X
 Occ3D
Occ3D
