Pix4Point: Image Pretrained Standard Transformers for 3D Point Cloud Understanding
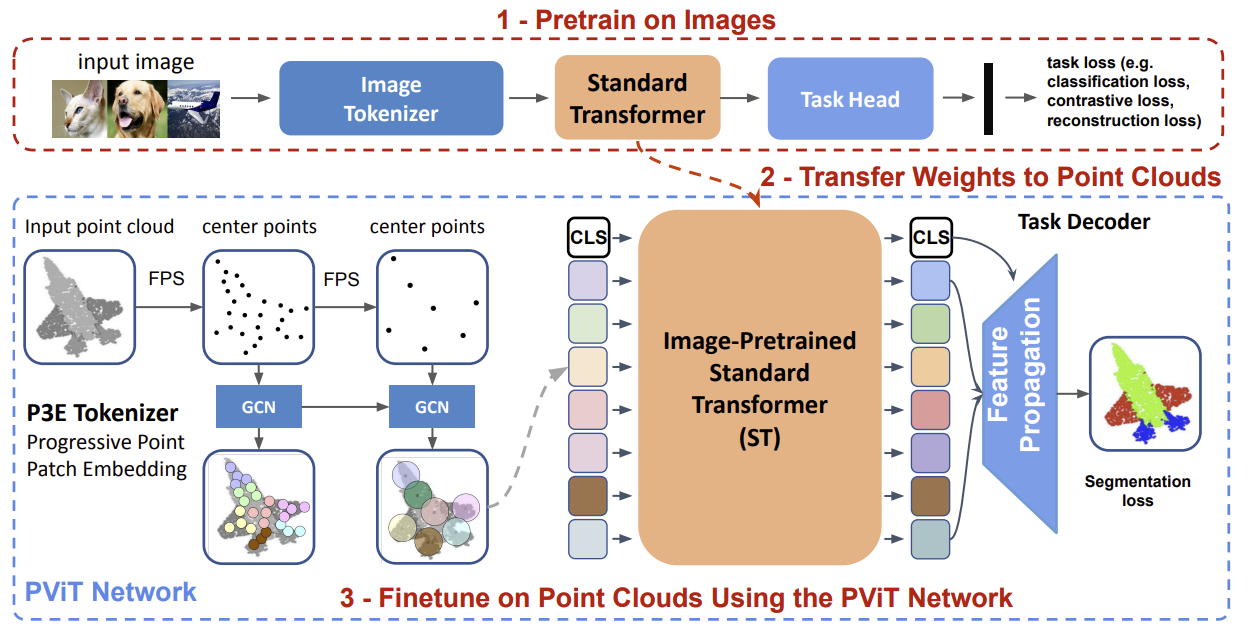
While Transformers have achieved impressive success in natural language processing and computer vision, their performance on 3D point clouds is relatively poor. This is mainly due to the limitation of Transformers: a demanding need for extensive training data. Unfortunately, in the realm of 3D point clouds, the availability of large datasets is a challenge, exacerbating the issue of training Transformers for 3D tasks. In this work, we solve the data issue of point cloud Transformers from two perspectives: (i) introducing more inductive bias to reduce the dependency of Transformers on data, and (ii) relying on cross-modality pretraining. More specifically, we first present Progressive Point Patch Embedding and present a new point cloud Transformer model namely PViT. PViT shares the same backbone as Transformer but is shown to be less hungry for data, enabling Transformer to achieve performance comparable to the state-of-the-art. Second, we formulate a simple yet effective pipeline dubbed "Pix4Point" that allows harnessing Transformers pretrained in the image domain to enhance downstream point cloud understanding. This is achieved through a modality-agnostic Transformer backbone with the help of a tokenizer and decoder specialized in the different domains. Pretrained on a large number of widely available images, significant gains of PViT are observed in the tasks of 3D point cloud classification, part segmentation, and semantic segmentation on ScanObjectNN, ShapeNetPart, and S3DIS, respectively. Our code and models are available at https://github.com/guochengqian/Pix4Point .
PDF Abstract


 ImageNet
ImageNet
 S3DIS
S3DIS
 ScanObjectNN
ScanObjectNN
