 Board Game Models
Board Game Models
MuZero
Introduced by Schrittwieser et al. in Mastering Atari, Go, Chess and Shogi by Planning with a Learned ModelMuZero is a model-based reinforcement learning algorithm. It builds upon AlphaZero's search and search-based policy iteration algorithms, but incorporates a learned model into the training procedure.
The main idea of the algorithm is to predict those aspects of the future that are directly relevant for planning. The model receives the observation (e.g. an image of the Go board or the Atari screen) as an input and transforms it into a hidden state. The hidden state is then updated iteratively by a recurrent process that receives the previous hidden state and a hypothetical next action. At every one of these steps the model predicts the policy (e.g. the move to play), value function (e.g. the predicted winner), and immediate reward (e.g. the points scored by playing a move). The model is trained end-to-end, with the sole objective of accurately estimating these three important quantities, so as to match the improved estimates of policy and value generated by search as well as the observed reward.
There is no direct constraint or requirement for the hidden state to capture all information necessary to reconstruct the original observation, drastically reducing the amount of information the model has to maintain and predict; nor is there any requirement for the hidden state to match the unknown, true state of the environment; nor any other constraints on the semantics of state. Instead, the hidden states are free to represent state in whatever way is relevant to predicting current and future values and policies. Intuitively, the agent can invent, internally, the rules or dynamics that lead to most accurate planning.
Source: Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model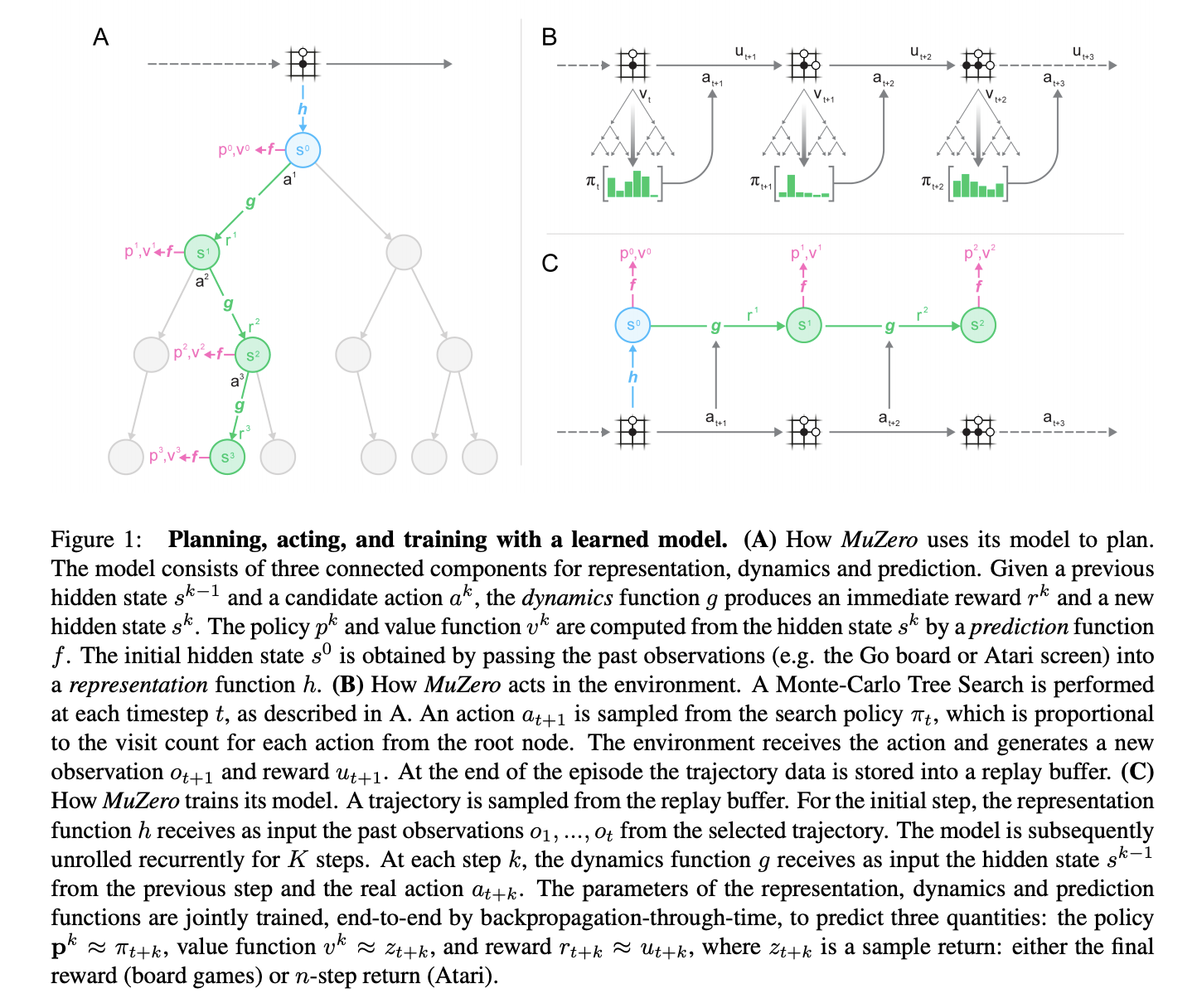
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Reinforcement Learning (RL) | 17 | 22.37% |
| Model-based Reinforcement Learning | 16 | 21.05% |
| Board Games | 6 | 7.89% |
| Atari Games | 5 | 6.58% |
| Continuous Control | 5 | 6.58% |
| Decision Making | 4 | 5.26% |
| Game of Go | 4 | 5.26% |
| Offline RL | 3 | 3.95% |
| Starcraft | 2 | 2.63% |
 Average Pooling
Average Pooling
 Convolution
Convolution
 Monte-Carlo Tree Search
Monte-Carlo Tree Search
 Prioritized Experience Replay
Prioritized Experience Replay
 Residual Block
Residual Block
