Vision-Language Pre-training: Basics, Recent Advances, and Future Trends
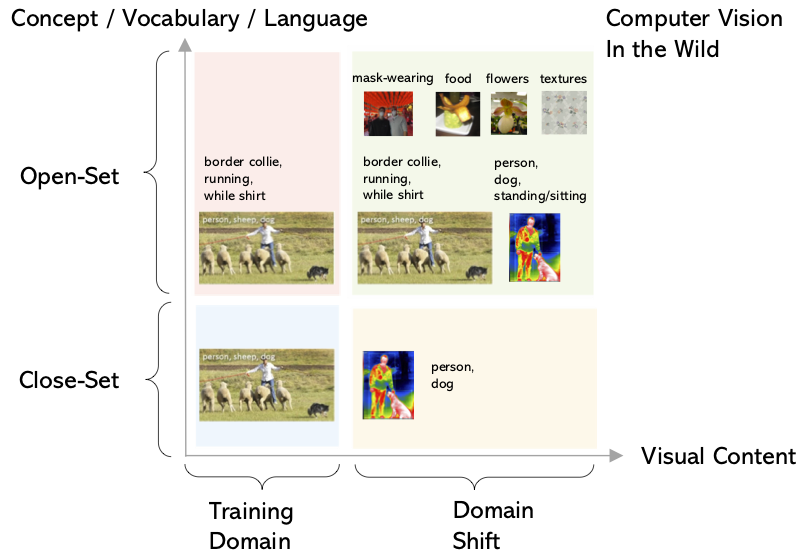
This paper surveys vision-language pre-training (VLP) methods for multimodal intelligence that have been developed in the last few years. We group these approaches into three categories: ($i$) VLP for image-text tasks, such as image captioning, image-text retrieval, visual question answering, and visual grounding; ($ii$) VLP for core computer vision tasks, such as (open-set) image classification, object detection, and segmentation; and ($iii$) VLP for video-text tasks, such as video captioning, video-text retrieval, and video question answering. For each category, we present a comprehensive review of state-of-the-art methods, and discuss the progress that has been made and challenges still being faced, using specific systems and models as case studies. In addition, for each category, we discuss advanced topics being actively explored in the research community, such as big foundation models, unified modeling, in-context few-shot learning, knowledge, robustness, and computer vision in the wild, to name a few.
PDF AbstractCode
 Spaces
Spaces







Datasets
 ImageNet
ImageNet
 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 Kinetics
Kinetics
 Visual Genome
Visual Genome
 DAVIS
DAVIS
 CLEVR
CLEVR
 MSR-VTT
test
MSR-VTT
test
 LVIS
LVIS
 GQA
GQA
 Conceptual Captions
Conceptual Captions
 OK-VQA
OK-VQA
 HowTo100M
HowTo100M
 ActivityNet Captions
ActivityNet Captions
 TextVQA
TextVQA
 DiDeMo
DiDeMo
 WebVid
WebVid
 VCR
VCR
 NoCaps
NoCaps
 VizWiz
VizWiz
 Objects365
Objects365
 LAION-400M
LAION-400M
 TVQA
TVQA
 A-OKVQA
A-OKVQA
 CC12M
CC12M
 VATEX
VATEX
 ActivityNet-QA
ActivityNet-QA
 NExT-QA
TextCaps
Winoground
NExT-QA
TextCaps
Winoground
 Localized Narratives
Localized Narratives
 TVQA+
TVQA+
 CrossTask
CrossTask
 Image Paragraph Captioning
Image Paragraph Captioning
 RedCaps
RedCaps
 KVQA
TVR
KVQA
TVR
 VALUE
VALUE
 PhraseCut
PhraseCut
 WebQA
WebQA
 How2QA
ELEVATER
How2QA
ELEVATER
 Violin
Violin
 TVC
TVC
 VALSE
VALSE
 GRIT
DramaQA
GRIT
DramaQA
 How2R
How2R
 WinoGAViL
WinoGAViL
