Search Results for author:
Found 123 papers, 49 papers with code
Box2Seg: Attention Weighted Loss and Discriminative Feature Learning for Weakly Supervised Segmentation
We propose a weakly supervised approach to semantic segmentation using bounding box annotations.

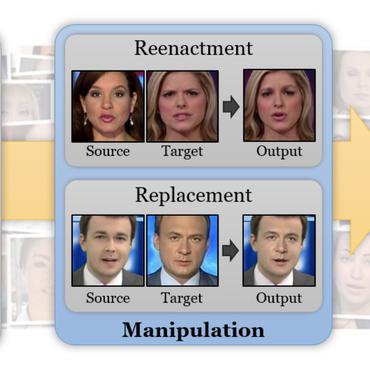
Energy-Latency Manipulation of Multi-modal Large Language Models via Verbose Samples
For verbose videos, a frame feature diversity loss is proposed to increase the feature diversity among frames.
An MRP Formulation for Supervised Learning: Generalized Temporal Difference Learning Models
In traditional statistical learning, data points are usually assumed to be independently and identically distributed (i. i. d.)

kNN-CLIP: Retrieval Enables Training-Free Segmentation on Continually Expanding Large Vocabularies
Rapid advancements in continual segmentation have yet to bridge the gap of scaling to large continually expanding vocabularies under compute-constrained scenarios.

Latent Guard: a Safety Framework for Text-to-image Generation
Hence, we propose Latent Guard, a framework designed to improve safety measures in text-to-image generation.


AnimateZoo: Zero-shot Video Generation of Cross-Species Animation via Subject Alignment
In this paper, we present AnimateZoo, a zero-shot diffusion-based video generator to address this challenging cross-species animation issue, aiming to accurately produce animal animations while preserving the background.

Red Teaming GPT-4V: Are GPT-4V Safe Against Uni/Multi-Modal Jailbreak Attacks?
Various jailbreak attacks have been proposed to red-team Large Language Models (LLMs) and revealed the vulnerable safeguards of LLMs.
Model-agnostic Origin Attribution of Generated Images with Few-shot Examples
In this work, we study the origin attribution of generated images in a practical setting where only a few images generated by a source model are available and the source model cannot be accessed.
DreamPolisher: Towards High-Quality Text-to-3D Generation via Geometric Diffusion
We present DreamPolisher, a novel Gaussian Splatting based method with geometric guidance, tailored to learn cross-view consistency and intricate detail from textual descriptions.
RoDLA: Benchmarking the Robustness of Document Layout Analysis Models
To address this, we are the first to introduce a robustness benchmark for DLA models, which includes 450K document images of three datasets.

On Pretraining Data Diversity for Self-Supervised Learning
We explore the impact of training with more diverse datasets, characterized by the number of unique samples, on the performance of self-supervised learning (SSL) under a fixed computational budget.

As Firm As Their Foundations: Can open-sourced foundation models be used to create adversarial examples for downstream tasks?
Foundation models pre-trained on web-scale vision-language data, such as CLIP, are widely used as cornerstones of powerful machine learning systems.

DetToolChain: A New Prompting Paradigm to Unleash Detection Ability of MLLM
We present DetToolChain, a novel prompting paradigm, to unleash the zero-shot object detection ability of multimodal large language models (MLLMs), such as GPT-4V and Gemini.
VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
This results in a significant disparity in scale compared to the vast quantities of other types of data.
A Simple Mixture Policy Parameterization for Improving Sample Efficiency of CVaR Optimization
Reinforcement learning algorithms utilizing policy gradients (PG) to optimize Conditional Value at Risk (CVaR) face significant challenges with sample inefficiency, hindering their practical applications.
An Image Is Worth 1000 Lies: Adversarial Transferability across Prompts on Vision-Language Models
Given that VLMs rely on prompts to adapt to different tasks, an intriguing question emerges: Can a single adversarial image mislead all predictions of VLMs when a thousand different prompts are given?
GaussCtrl: Multi-View Consistent Text-Driven 3D Gaussian Splatting Editing
We propose GaussCtrl, a text-driven method to edit a 3D scene reconstructed by the 3D Gaussian Splatting (3DGS).
CAT: Enhancing Multimodal Large Language Model to Answer Questions in Dynamic Audio-Visual Scenarios
This paper focuses on the challenge of answering questions in scenarios that are composed of rich and complex dynamic audio-visual components.

 Audio-visual Question Answering
Audio-Visual Question Answering (AVQA)
+5
Audio-visual Question Answering
Audio-Visual Question Answering (AVQA)
+5
Lifelong Benchmarks: Efficient Model Evaluation in an Era of Rapid Progress
However, with repeated testing, the risk of overfitting grows as algorithms over-exploit benchmark idiosyncrasies.
Stop Reasoning! When Multimodal LLMs with Chain-of-Thought Reasoning Meets Adversarial Images
Our research evaluates the adversarial robustness of MLLMs when employing CoT reasoning, finding that CoT marginally improves adversarial robustness against existing attack methods.
Corrective Machine Unlearning
We hope our work spurs research towards developing better methods for corrective unlearning and offers practitioners a new strategy to handle data integrity challenges arising from web-scale training.
Can Large Language Model Agents Simulate Human Trust Behaviors?
In addition, we probe into the biases in agent trust and the differences in agent trust towards agents and humans.

SynthCLIP: Are We Ready for a Fully Synthetic CLIP Training?
We present SynthCLIP, a novel framework for training CLIP models with entirely synthetic text-image pairs, significantly departing from previous methods relying on real data.
Inducing High Energy-Latency of Large Vision-Language Models with Verbose Images
Once attackers maliciously induce high energy consumption and latency time (energy-latency cost) during inference of VLMs, it will exhaust computational resources.
Measuring Value Alignment
As artificial intelligence (AI) systems become increasingly integrated into various domains, ensuring that they align with human values becomes critical.


Scene-Conditional 3D Object Stylization and Composition
Recently, 3D generative models have made impressive progress, enabling the generation of almost arbitrary 3D assets from text or image inputs.
CLIP as RNN: Segment Countless Visual Concepts without Training Endeavor
Mask labels are labor-intensive, which limits the number of categories in segmentation datasets.
Label Delay in Online Continual Learning
We introduce a new continual learning framework with explicit modeling of the label delay between data and label streams over time steps.

Improving Adversarial Transferability via Model Alignment
During the alignment process, the parameters of the source model are fine-tuned to minimize an alignment loss.
Understanding and Improving In-Context Learning on Vision-language Models
Our findings indicate that ICL in VLMs is predominantly driven by the textual information in the demonstrations whereas the visual information in the demonstrations barely affects the ICL performance.
Self-Discovering Interpretable Diffusion Latent Directions for Responsible Text-to-Image Generation
A risk with these models is the potential generation of inappropriate content, such as biased or harmful images.
Managing AI Risks in an Era of Rapid Progress
In this short consensus paper, we outline risks from upcoming, advanced AI systems.
A Survey on Transferability of Adversarial Examples across Deep Neural Networks
This survey explores the landscape of the adversarial transferability of adversarial examples.
Real-Fake: Effective Training Data Synthesis Through Distribution Matching
Synthetic training data has gained prominence in numerous learning tasks and scenarios, offering advantages such as dataset augmentation, generalization evaluation, and privacy preservation.
Beyond Training Objectives: Interpreting Reward Model Divergence in Large Language Models
Large language models (LLMs) fine-tuned by reinforcement learning from human feedback (RLHF) are becoming more widely deployed.
PoRF: Pose Residual Field for Accurate Neural Surface Reconstruction
On the MobileBrick dataset that contains casually captured unbounded 360-degree videos, our method refines ARKit poses and improves the reconstruction F1 score from 69. 18 to 75. 67, outperforming that with the dataset provided ground-truth pose (75. 14).
AttributionLab: Faithfulness of Feature Attribution Under Controllable Environments
Feature attribution explains neural network outputs by identifying relevant input features.
Exploring Non-additive Randomness on ViT against Query-Based Black-Box Attacks
In this work, we first taxonomize the stochastic defense strategies against QBBA.
Neural Collapse Terminus: A Unified Solution for Class Incremental Learning and Its Variants
Beyond the normal case, long-tail class incremental learning and few-shot class incremental learning are also proposed to consider the data imbalance and data scarcity, respectively, which are common in real-world implementations and further exacerbate the well-known problem of catastrophic forgetting.

A Systematic Survey of Prompt Engineering on Vision-Language Foundation Models
This paper aims to provide a comprehensive survey of cutting-edge research in prompt engineering on three types of vision-language models: multimodal-to-text generation models (e. g. Flamingo), image-text matching models (e. g.
OxfordTVG-HIC: Can Machine Make Humorous Captions from Images?
Hence, humour generation and understanding can serve as a new task for evaluating the ability of deep-learning methods to process abstract and subjective information.
ReMaX: Relaxing for Better Training on Efficient Panoptic Segmentation
This paper presents a new mechanism to facilitate the training of mask transformers for efficient panoptic segmentation, democratizing its deployment.
Reliable Evaluation of Adversarial Transferability
Adversarial examples (AEs) with small adversarial perturbations can mislead deep neural networks (DNNs) into wrong predictions.
Graph Inductive Biases in Transformers without Message Passing
Graph inductive biases are crucial for Graph Transformers, and previous works incorporate them using message-passing modules and/or positional encodings.
 Ranked #1 on
Node Classification
on PATTERN
Ranked #1 on
Node Classification
on PATTERN

Provably Correct Physics-Informed Neural Networks
Recent work provides promising evidence that Physics-informed neural networks (PINN) can efficiently solve partial differential equations (PDE).
Online Continual Learning Without the Storage Constraint
In this paper, we target such applications, investigating the online continual learning problem under relaxed storage constraints and limited computational budgets.
Towards Robust Prompts on Vision-Language Models
With the advent of vision-language models (VLMs) that can perform in-context and prompt-based learning, how can we design prompting approaches that robustly generalize to distribution shift and can be used on novel classes outside the support set of the prompts?
Influencer Backdoor Attack on Semantic Segmentation
In this work, we explore backdoor attacks on segmentation models to misclassify all pixels of a victim class by injecting a specific trigger on non-victim pixels during inferences, which is dubbed Influencer Backdoor Attack (IBA).
Reliability in Semantic Segmentation: Are We on the Right Track?
We analyze a broad variety of models, spanning from older ResNet-based architectures to novel transformers and assess their reliability based on four metrics: robustness, calibration, misclassification detection and out-of-distribution (OOD) detection.
PhysFormer++: Facial Video-based Physiological Measurement with SlowFast Temporal Difference Transformer
As key modules in PhysFormer, the temporal difference transformers first enhance the quasi-periodic rPPG features with temporal difference guided global attention, and then refine the local spatio-temporal representation against interference.
Neural Collapse Inspired Feature-Classifier Alignment for Few-Shot Class Incremental Learning
In this paper, we deal with this misalignment dilemma in FSCIL inspired by the recently discovered phenomenon named neural collapse, which reveals that the last-layer features of the same class will collapse into a vertex, and the vertices of all classes are aligned with the classifier prototypes, which are formed as a simplex equiangular tight frame (ETF).
Neural Collapse Inspired Feature-Classifier Alignment for Few-Shot Class-Incremental Learning
In this paper, we deal with this misalignment dilemma in FSCIL inspired by the recently discovered phenomenon named neural collapse, which reveals that the last-layer features of the same class will collapse into a vertex, and the vertices of all classes are aligned with the classifier prototypes, which are formed as a simplex equiangular tight frame (ETF).
 Ranked #3 on
Few-Shot Class-Incremental Learning
on CUB-200-2011
Ranked #3 on
Few-Shot Class-Incremental Learning
on CUB-200-2011
Not Just Pretty Pictures: Toward Interventional Data Augmentation Using Text-to-Image Generators
Neural image classifiers are known to undergo severe performance degradation when exposed to inputs that exhibit covariate shifts with respect to the training distribution.

General Adversarial Defense Against Black-box Attacks via Pixel Level and Feature Level Distribution Alignments
In this paper, we use Deep Generative Networks (DGNs) with a novel training mechanism to eliminate the distribution gap.
LUMix: Improving Mixup by Better Modelling Label Uncertainty
LUMix is simple as it can be implemented in just a few lines of code and can be universally applied to any deep networks \eg CNNs and Vision Transformers, with minimal computational cost.

Is synthetic data from generative models ready for image recognition?
Recent text-to-image generation models have shown promising results in generating high-fidelity photo-realistic images.

Diversified Dynamic Routing for Vision Tasks
Deep learning models for vision tasks are trained on large datasets under the assumption that there exists a universal representation that can be used to make predictions for all samples.

SegPGD: An Effective and Efficient Adversarial Attack for Evaluating and Boosting Segmentation Robustness
Since SegPGD can create more effective adversarial examples, the adversarial training with our SegPGD can boost the robustness of segmentation models.
Collaborative Quantization Embeddings for Intra-Subject Prostate MR Image Registration
Image registration is useful for quantifying morphological changes in longitudinal MR images from prostate cancer patients.

MP2: A Momentum Contrast Approach for Recommendation with Pointwise and Pairwise Learning
To alleviate the influence of the annotation bias, we perform a momentum update to ensure a consistent item representation.
Unsupervised Contrastive Domain Adaptation for Semantic Segmentation
Semantic segmentation models struggle to generalize in the presence of domain shift.

Task-Agnostic Robust Representation Learning
To tackle this problem, a great amount of research has been done to study the training procedure of a network to improve its robustness.

Language Matters: A Weakly Supervised Vision-Language Pre-training Approach for Scene Text Detection and Spotting
Our network consists of an image encoder and a character-aware text encoder that extract visual and textual features, respectively, as well as a visual-textual decoder that models the interaction among textual and visual features for learning effective scene text representations.
Optical Character Recognition
 Optical Character Recognition (OCR)
+2
Optical Character Recognition (OCR)
+2
Gradients without Backpropagation
Using backpropagation to compute gradients of objective functions for optimization has remained a mainstay of machine learning.
Deeply Explain CNN via Hierarchical Decomposition
The proposed framework can generate a deep hierarchy of strongly associated supporting evidence for the network decision, which provides insight into the decision-making process.
Towards Adversarial Evaluations for Inexact Machine Unlearning
Machine Learning models face increased concerns regarding the storage of personal user data and adverse impacts of corrupted data like backdoors or systematic bias.
Mimicking the Oracle: An Initial Phase Decorrelation Approach for Class Incremental Learning
Specifically, we experimentally show that directly encouraging CIL Learner at the initial phase to output similar representations as the model jointly trained on all classes can greatly boost the CIL performance.
A Continuous Mapping For Augmentation Design
Automated data augmentation (ADA) techniques have played an important role in boosting the performance of deep models.
Looking Beyond Single Images for Contrastive Semantic Segmentation Learning
We present an approach to contrastive representation learning for semantic segmentation.
Overcoming the Convex Barrier for Simplex Inputs
Recent progress in neural network verification has challenged the notion of a convex barrier, that is, an inherent weakness in the convex relaxation of the output of a neural network.
PhysFormer: Facial Video-based Physiological Measurement with Temporal Difference Transformer
Remote photoplethysmography (rPPG), which aims at measuring heart activities and physiological signals from facial video without any contact, has great potential in many applications (e. g., remote healthcare and affective computing).
Hierarchical interaction network for video object segmentation from referring expressions
In this paper, we investigate the problem of video object segmentation from referring expressions (VOSRE).
 Ranked #1 on
Referring Expression Segmentation
on J-HMDB
(Precision@0.9 metric)
Ranked #1 on
Referring Expression Segmentation
on J-HMDB
(Precision@0.9 metric)
 Optical Flow Estimation
Optical Flow Estimation
 Referring Expression Segmentation
+3
Referring Expression Segmentation
+3
Adversarial Examples on Segmentation Models Can be Easy to Transfer
The high transferability achieved by our method shows that, in contrast to the observations in previous work, adversarial examples on a segmentation model can be easy to transfer to other segmentation models.
TransMix: Attend to Mix for Vision Transformers
The confidence of the label will be larger if the corresponding input image is weighted higher by the attention map.
Mix-MaxEnt: Creating High Entropy Barriers To Improve Accuracy and Uncertainty Estimates of Deterministic Neural Networks
We propose an extremely simple approach to regularize a single deterministic neural network to obtain improved accuracy and reliable uncertainty estimates.
Towards fast and effective single-step adversarial training
In this work, we methodically revisit the role of noise and clipping in single-step adversarial training.
Shape-Tailored Deep Neural Networks With PDEs
ST-DNN are deep networks formulated through the use of partial differential equations (PDE) to be defined on arbitrarily shaped regions.
Vision Transformer with Progressive Sampling
As a typical example, the Vision Transformer (ViT) directly applies a pure transformer architecture on image classification, by simply splitting images into tokens with a fixed length, and employing transformers to learn relations between these tokens.
Multilevel Knowledge Transfer for Cross-Domain Object Detection
The key ingredients to our approach are -- (a) mapping the source to the target domain on pixel-level; (b) training a teacher network on the mapped source and the unannotated target domain using adversarial feature alignment; and (c) finally training a student network using the pseudo-labels obtained from the teacher.
Open-World Entity Segmentation
By removing the need of class label prediction, the models trained for such task can focus more on improving segmentation quality.
Communicating via Markov Decision Processes
We contribute a theoretically grounded approach to MCGs based on maximum entropy reinforcement learning and minimum entropy coupling that we call MEME.
Class-Agnostic Segmentation Loss and Its Application to Salient Object Detection and Segmentation
For low-fidelity training data (incorrect class label) class-agnostic segmentation loss outperforms the state-of-the-art methods on salient object detection datasets by staggering margins of around 50%.
Visual Parser: Representing Part-whole Hierarchies with Transformers
To model the representations of the two levels, we first encode the information from the whole into part vectors through an attention mechanism, then decode the global information within the part vectors back into the whole representation.
 Ranked #313 on
Image Classification
on ImageNet
Ranked #313 on
Image Classification
on ImageNet
Large-scale Unsupervised Semantic Segmentation
In this work, we propose a new problem of large-scale unsupervised semantic segmentation (LUSS) with a newly created benchmark dataset to help the research progress.
 Ranked #1 on
Unsupervised Semantic Segmentation
on ImageNet-S-300
Ranked #1 on
Unsupervised Semantic Segmentation
on ImageNet-S-300
General Adversarial Defense via Pixel Level and Feature Level Distribution Alignment
Specifically, compared with previous methods, we propose a more efficient pixel-level training constraint to weaken the hardness of aligning adversarial samples to clean samples, which can thus obviously enhance the robustness on adversarial samples.
How Benign is Benign Overfitting ?
We investigate two causes for adversarial vulnerability in deep neural networks: bad data and (poorly) trained models.
Shape-Tailored Deep Neural Networks Using PDEs for Segmentation
We present Shape-Tailored Deep Neural Networks (ST-DNN).
Don't be picky, all students in the right family can learn from good teachers
State-of-the-art results in deep learning have been improving steadily, in good part due to the use of larger models.
Point Transformer
For example, on the challenging S3DIS dataset for large-scale semantic scene segmentation, the Point Transformer attains an mIoU of 70. 4% on Area 5, outperforming the strongest prior model by 3. 3 absolute percentage points and crossing the 70% mIoU threshold for the first time.
 Ranked #3 on
3D Semantic Segmentation
on STPLS3D
Ranked #3 on
3D Semantic Segmentation
on STPLS3D


STEER : Simple Temporal Regularization For Neural ODE
Training Neural Ordinary Differential Equations (ODEs) is often computationally expensive.

Learning to Sample the Most Useful Training Patches from Images
Some image restoration tasks like demosaicing require difficult training samples to learn effective models.
Class-Agnostic Segmentation Loss and Its Application to Salient Object Detection and Segmentation
For low-fidelity training data (incorrect class label) class-agnostic segmentation loss outperforms the state-of-the-art methods on salient object detection datasets by staggering margins of around 50%.
Diagnosing and Preventing Instabilities in Recurrent Video Processing
Recurrent models are a popular choice for video enhancement tasks such as video denoising or super-resolution.


HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking
Multi-Object Tracking (MOT) has been notoriously difficult to evaluate.
Many-shot from Low-shot: Learning to Annotate using Mixed Supervision for Object Detection
Object detection has witnessed significant progress by relying on large, manually annotated datasets.

Simulation-Based Inference for Global Health Decisions
The COVID-19 pandemic has highlighted the importance of in-silico epidemiological modelling in predicting the dynamics of infectious diseases to inform health policy and decision makers about suitable prevention and containment strategies.

Using Hindsight to Anchor Past Knowledge in Continual Learning
In continual learning, the learner faces a stream of data whose distribution changes over time.
Global Texture Enhancement for Fake Face Detection in the Wild
In this paper, we conduct an empirical study on fake/real faces, and have two important observations: firstly, the texture of fake faces is substantially different from real ones; secondly, global texture statistics are more robust to image editing and transferable to fake faces from different GANs and datasets.

Domain-invariant Stereo Matching Networks
State-of-the-art stereo matching networks have difficulties in generalizing to new unseen environments due to significant domain differences, such as color, illumination, contrast, and texture.
Efficient Bayesian Inference for Nested Simulators
We introduce two approaches for conducting efficient Bayesian inference in stochastic simulators containing nested stochastic sub-procedures, i. e., internal procedures for which the density cannot be calculated directly such as rejection sampling loops.
ShardNet: One Filter Set to Rule Them All
Deep CNNs have achieved state-of-the-art performance for numerous machine learning and computer vision tasks in recent years, but as they have become increasingly deep, the number of parameters they use has also increased, making them hard to deploy in memory-constrained environments and difficult to interpret.
The Intriguing Effects of Focal Loss on the Calibration of Deep Neural Networks
When combined with temperature scaling, focal loss, whilst preserving accuracy and yielding state-of-the-art calibrated models, also preserves the confidence of the model's correct predictions, which is extremely desirable for downstream tasks.
Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale
Probabilistic programming languages (PPLs) are receiving widespread attention for performing Bayesian inference in complex generative models.

Let's Take This Online: Adapting Scene Coordinate Regression Network Predictions for Online RGB-D Camera Relocalisation
Many applications require a camera to be relocalised online, without expensive offline training on the target scene.

Res2Net: A New Multi-scale Backbone Architecture
We evaluate the Res2Net block on all these models and demonstrate consistent performance gains over baseline models on widely-used datasets, e. g., CIFAR-100 and ImageNet.
 Ranked #2 on
Image Classification
on GasHisSDB
Ranked #2 on
Image Classification
on GasHisSDB
Efficient Probabilistic Inference in the Quest for Physics Beyond the Standard Model
We present a novel probabilistic programming framework that couples directly to existing large-scale simulators through a cross-platform probabilistic execution protocol, which allows general-purpose inference engines to record and control random number draws within simulators in a language-agnostic way.
DGPose: Deep Generative Models for Human Body Analysis
However, the latent space learned by such approaches is typically not interpretable, resulting in less flexibility.

Long-term Tracking in the Wild: A Benchmark
We introduce the OxUvA dataset and benchmark for evaluating single-object tracking algorithms.

A Projected Gradient Descent Method for CRF Inference allowing End-To-End Training of Arbitrary Pairwise Potentials
It is empirically demonstrated that such learned potentials can improve segmentation accuracy and that certain label class interactions are indeed better modelled by a non-Gaussian potential.
Bottom-Up Top-Down Cues for Weakly-Supervised Semantic Segmentation
We focus on the following three aspects of EM: (i) initialization; (ii) latent posterior estimation (E-step) and (iii) the parameter update (M-step).
Weakly supervised Semantic Segmentation
 Weakly-Supervised Semantic Segmentation
Weakly-Supervised Semantic Segmentation
Online Real-time Multiple Spatiotemporal Action Localisation and Prediction
To the best of our knowledge, ours is the first real-time (up to 40fps) system able to perform online S/T action localisation and early action prediction on the untrimmed videos of UCF101-24.
Deeply supervised salient object detection with short connections
Recent progress on saliency detection is substantial, benefiting mostly from the explosive development of Convolutional Neural Networks (CNNs).
 Ranked #4 on
RGB Salient Object Detection
on SBU
Ranked #4 on
RGB Salient Object Detection
on SBU
Learning to Navigate the Energy Landscape
We demonstrate the efficacy of our approach on the challenging problem of RGB Camera Relocalization.

Joint Object-Material Category Segmentation from Audio-Visual Cues
It is not always possible to recognise objects and infer material properties for a scene from visual cues alone, since objects can look visually similar whilst being made of very different materials.
Staple: Complementary Learners for Real-Time Tracking
Correlation Filter-based trackers have recently achieved excellent performance, showing great robustness to challenging situations exhibiting motion blur and illumination changes.
![]() Ranked #28 on
Visual Object Tracking
on TrackingNet
Ranked #28 on
Visual Object Tracking
on TrackingNet
Prototypical Priors: From Improving Classification to Zero-Shot Learning
Recent works on zero-shot learning make use of side information such as visual attributes or natural language semantics to define the relations between output visual classes and then use these relationships to draw inference on new unseen classes at test time.


Higher Order Conditional Random Fields in Deep Neural Networks
Recent deep learning approaches have incorporated CRFs into Convolutional Neural Networks (CNNs), with some even training the CRF end-to-end with the rest of the network.
 Ranked #56 on
Semantic Segmentation
on PASCAL Context
Ranked #56 on
Semantic Segmentation
on PASCAL Context
BING: Binarized Normed Gradients for Objectness Estimation at 300fps
Training a generic objectness measure to produce a small set of candidate object windows, has been shown to speed up the classical sliding window object detection paradigm.
Efficient Semidefinite Branch-and-Cut for MAP-MRF Inference
We propose a Branch-and-Cut (B&C) method for solving general MAP-MRF inference problems.
Higher Order Priors for Joint Intrinsic Image, Objects, and Attributes Estimation
Many methods have been proposed to recover the intrinsic scene properties such as shape, reflectance and illumination from a single image.
ImageSpirit: Verbal Guided Image Parsing
This allows us to formulate the image parsing problem as one of jointly estimating per-pixel object and attribute labels from a set of training images.
Learning Anchor Planes for Classification
It provides a set of anchor points which form a local coordinate system, such that each data point on the manifold can be approximated by a linear combination of its anchor points, and the linear weights become the local coordinate coding.
Improved Moves for Truncated Convex Models
Compared to previous approaches based on the LP relaxation, e. g. interior-point algorithms or tree-reweighted message passing (TRW), our method is faster as it uses only the efficient st-mincut algorithm in its design.
