Search Results for author:
Found 487 papers, 170 papers with code
OIE@OIA: an Adaptable and Efficient Open Information Extraction Framework
OIE@OIA follows the methodology of Open Information eXpression (OIX): parsing a sentence to an Open Information Annotation (OIA) Graph and then adapting the OIA graph to different OIE tasks with simple rules.
A Predicate-Function-Argument Annotation of Natural Language for Open-Domain Information eXpression
Based on the same platform of OIX, the OIE strategies are reusable, and people can select a set of strategies to assemble their algorithm for a specific task so that the adaptability may be significantly increased.
AI-Face: A Million-Scale Demographically Annotated AI-Generated Face Dataset and Fairness Benchmark
However, no existing dataset comprehensively encompasses both demographic attributes and diverse generative methods, which hinders the development of fair detectors for AI-generated faces.

Augmenting Textual Generation via Topology Aware Retrieval
This framework includes a retrieval module that selects texts based on their topological relationships and an aggregation module that integrates these texts into prompts to stimulate LLMs for text generation.

Balancing User Preferences by Social Networks: A Condition-Guided Social Recommendation Model for Mitigating Popularity Bias
More specifically, CGSoRec first includes a Condition-Guided Social Denoising Model (CSD) to remove redundant social relations in the social network for capturing users' social preferences with items more precisely.

Causal-Aware Graph Neural Architecture Search under Distribution Shifts
We propose to handle the distribution shifts in the graph architecture search process by discovering and exploiting the causal relationship between graphs and architectures to search for the optimal architectures that can generalize under distribution shifts.


UU-Mamba: Uncertainty-aware U-Mamba for Cardiac Image Segmentation
Biomedical image segmentation is critical for accurate identification and analysis of anatomical structures in medical imaging, particularly in cardiac MRI.
Rethinking Independent Cross-Entropy Loss For Graph-Structured Data
We learn the joint distribution of node and cluster labels conditioned on their representations, and train GNNs with the obtained joint loss.

Unsupervised Multimodal Clustering for Semantics Discovery in Multimodal Utterances
UMC shows remarkable improvements of 2-6\% scores in clustering metrics over state-of-the-art methods, marking the first successful endeavor in this domain.


DisenStudio: Customized Multi-subject Text-to-Video Generation with Disentangled Spatial Control
To tackle the problems, in this paper, we propose DisenStudio, a novel framework that can generate text-guided videos for customized multiple subjects, given few images for each subject.
EPPS: Advanced Polyp Segmentation via Edge Information Injection and Selective Feature Decoupling
Furthermore, we introduce a component called Selective Feature Decoupler (SFD) to suppress the influence of noise and extraneous features on the model.
Combining multiple post-training techniques to achieve most efficient quantized LLMs
Large Language Models (LLMs) have distinguished themselves with outstanding performance in complex language modeling tasks, yet they come with significant computational and storage challenges.

Efficient Sharpness-aware Minimization for Molecular Graph Transformer Models
Sharpness-aware minimization (SAM) has received increasing attention in computer vision since it can effectively eliminate the sharp local minima from the training trajectory and mitigate generalization degradation.
PrivSGP-VR: Differentially Private Variance-Reduced Stochastic Gradient Push with Tight Utility Bounds
In this paper, we propose a differentially private decentralized learning method (termed PrivSGP-VR) which employs stochastic gradient push with variance reduction and guarantees $(\epsilon, \delta)$-differential privacy (DP) for each node.
Tele-FLM Technical Report
Large language models (LLMs) have showcased profound capabilities in language understanding and generation, facilitating a wide array of applications.
Optimizing OOD Detection in Molecular Graphs: A Novel Approach with Diffusion Models
In this work, we propose to detect OOD molecules by adopting an auxiliary diffusion model-based framework, which compares similarities between input molecules and reconstructed graphs.
FedGreen: Carbon-aware Federated Learning with Model Size Adaptation
Federated learning (FL) provides a promising collaborative framework to build a model from distributed clients, and this work investigates the carbon emission of the FL process.
RealTCD: Temporal Causal Discovery from Interventional Data with Large Language Model
In the field of Artificial Intelligence for Information Technology Operations, causal discovery is pivotal for operation and maintenance of graph construction, facilitating downstream industrial tasks such as root cause analysis.

ID-Animator: Zero-Shot Identity-Preserving Human Video Generation
Based on this pipeline, a random face reference training method is further devised to precisely capture the ID-relevant embeddings from reference images, thus improving the fidelity and generalization capacity of our model for ID-specific video generation.

Mechanisms promoting biodiversity in ecosystems
Explaining biodiversity is a central focus in theoretical ecology.
FLARE: A New Federated Learning Framework with Adjustable Learning Rates over Resource-Constrained Wireless Networks
Wireless federated learning (WFL) suffers from heterogeneity prevailing in the data distributions, computing powers, and channel conditions of participating devices.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
We introduce phi-3-mini, a 3. 8 billion parameter language model trained on 3. 3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3. 5 (e. g., phi-3-mini achieves 69% on MMLU and 8. 38 on MT-bench), despite being small enough to be deployed on a phone.
Texture-aware and Shape-guided Transformer for Sequential DeepFake Detection
In this paper, we propose a novel Texture-aware and Shape-guided Transformer to enhance detection performance.

Robust CLIP-Based Detector for Exposing Diffusion Model-Generated Images
Diffusion models (DMs) have revolutionized image generation, producing high-quality images with applications spanning various fields.

Self-Selected Attention Span for Accelerating Large Language Model Inference
We demonstrate that using this custom CUDA kernel improves the throughput of LLM inference by 28%.
Fast Diffeomorphic Image Registration using Patch based Fully Convolutional Networks
Diffeomorphic image registration is a fundamental step in medical image analysis, owing to its capability to ensure the invertibility of transformations and preservation of topology.

The VoicePrivacy 2024 Challenge Evaluation Plan
The task of the challenge is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content and emotional states.
iMD4GC: Incomplete Multimodal Data Integration to Advance Precise Treatment Response Prediction and Survival Analysis for Gastric Cancer
The limited availability of modalities for each patient would cause information loss, adversely affecting predictive accuracy.


Qibo: A Large Language Model for Traditional Chinese Medicine
Furthermore, we develop the Qibo-benchmark, a specialized tool for evaluating the performance of LLMs, which is a specialized tool for evaluating the performance of LLMs in the TCM domain.
Exploring the Potential of Large Language Models in Graph Generation
In this paper, we propose LLM4GraphGen to explore the ability of LLMs for graph generation with systematical task designs and extensive experiments.

When Do We Not Need Larger Vision Models?
Our results show that a multi-scale smaller model has comparable learning capacity to a larger model, and pre-training smaller models with S$^2$ can match or even exceed the advantage of larger models.

MIntRec 2.0: A Large-scale Benchmark Dataset for Multimodal Intent Recognition and Out-of-scope Detection in Conversations
We believe that MIntRec 2. 0 will serve as a valuable resource, providing a pioneering foundation for research in human-machine conversational interactions, and significantly facilitating related applications.

Robust Light-Weight Facial Affective Behavior Recognition with CLIP
Human affective behavior analysis aims to delve into human expressions and behaviors to deepen our understanding of human emotions.
Robust COVID-19 Detection in CT Images with CLIP
In the realm of medical imaging, particularly for COVID-19 detection, deep learning models face substantial challenges such as the necessity for extensive computational resources, the paucity of well-annotated datasets, and a significant amount of unlabeled data.
SVD-LLM: Truncation-aware Singular Value Decomposition for Large Language Model Compression
The advancements in Large Language Models (LLMs) have been hindered by their substantial sizes, which necessitate LLM compression methods for practical deployment.
Optimizing Latent Graph Representations of Surgical Scenes for Zero-Shot Domain Transfer
Purpose: Advances in deep learning have resulted in effective models for surgical video analysis; however, these models often fail to generalize across medical centers due to domain shift caused by variations in surgical workflow, camera setups, and patient demographics.
UAV-Enabled Asynchronous Federated Learning
To exploit unprecedented data generation in mobile edge networks, federated learning (FL) has emerged as a promising alternative to the conventional centralized machine learning (ML).
Spectral Invariant Learning for Dynamic Graphs under Distribution Shifts
In this paper, we discover that there exist cases with distribution shifts unobservable in the time domain while observable in the spectral domain, and propose to study distribution shifts on dynamic graphs in the spectral domain for the first time.

Unsupervised Graph Neural Architecture Search with Disentangled Self-supervision
To address the challenge, we propose a novel Disentangled Self-supervised Graph Neural Architecture Search (DSGAS) model, which is able to discover the optimal architectures capturing various latent graph factors in a self-supervised fashion based on unlabeled graph data.
Electrocardiogram Instruction Tuning for Report Generation
Electrocardiogram (ECG) serves as the primary non-invasive diagnostic tool for cardiac conditions monitoring, are crucial in assisting clinicians.
Parameterized quantum comb and simpler circuits for reversing unknown qubit-unitary operations
Quantum comb is an essential tool for characterizing complex quantum protocols in quantum information processing.
Preserving Fairness Generalization in Deepfake Detection
The existing method for addressing this problem is providing a fair loss function.
Neural Radiance Fields in Medical Imaging: Challenges and Next Steps
Neural Radiance Fields (NeRF), as a pioneering technique in computer vision, offer great potential to revolutionize medical imaging by synthesizing three-dimensional representations from the projected two-dimensional image data.
Two-stage Cytopathological Image Synthesis for Augmenting Cervical Abnormality Screening
In the first Global Image Generation stage, a Normal Image Generator is designed to generate cytopathological images full of normal cervical cells.

HyCubE: Efficient Knowledge Hypergraph 3D Circular Convolutional Embedding
It is desirable and challenging for knowledge hypergraph embedding to reach a trade-off between model effectiveness and efficiency.
Rethinking Propagation for Unsupervised Graph Domain Adaptation
Motivated by our empirical analysis, we reevaluate the role of GNNs in graph domain adaptation and uncover the pivotal role of the propagation process in GNNs for adapting to different graph domains.

Failure Analysis in Next-Generation Critical Cellular Communication Infrastructures
The advent of communication technologies marks a transformative phase in critical infrastructure construction, where the meticulous analysis of failures becomes paramount in achieving the fundamental objectives of continuity, security, and availability.
Revisiting VAE for Unsupervised Time Series Anomaly Detection: A Frequency Perspective
To ensure an accurate AD, FCVAE exploits an innovative approach to concurrently integrate both the global and local frequency features into the condition of Conditional Variational Autoencoder (CVAE) to significantly increase the accuracy of reconstructing the normal data.

Artificial Intelligence in Image-based Cardiovascular Disease Analysis: A Comprehensive Survey and Future Outlook
Our review encompasses these modalities, giving a broad perspective on the diverse imaging techniques integrated with AI for CVD analysis.
Masked Conditional Diffusion Model for Enhancing Deepfake Detection
this paper present we put a new insight into diffusion model-based data augmentation, and propose a Masked Conditional Diffusion Model (MCDM) for enhancing deepfake detection.
Uncertainty-Aware Explainable Recommendation with Large Language Models
Providing explanations within the recommendation system would boost user satisfaction and foster trust, especially by elaborating on the reasons for selecting recommended items tailored to the user.

Active Generation Network of Human Skeleton for Action Recognition
To solve those problems, We propose a novel active generative network (AGN), which can adaptively learn various action categories by motion style transfer to generate new actions when the data for a particular action is only a single sample or few samples.

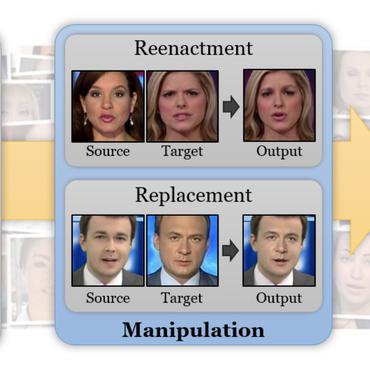
Detecting Multimedia Generated by Large AI Models: A Survey
The rapid advancement of Large AI Models (LAIMs), particularly diffusion models and large language models, has marked a new era where AI-generated multimedia is increasingly integrated into various aspects of daily life.
To deform or not: treatment-aware longitudinal registration for breast DCE-MRI during neoadjuvant chemotherapy via unsupervised keypoints detection
We use a clinical dataset with 1630 MRI scans from 314 patients treated with NAC.


Efficient Image Super-Resolution via Symmetric Visual Attention Network
An important development direction in the Single-Image Super-Resolution (SISR) algorithms is to improve the efficiency of the algorithms.
 Ranked #53 on
Image Super-Resolution
on Set14 - 4x upscaling
Ranked #53 on
Image Super-Resolution
on Set14 - 4x upscaling

TeleChat Technical Report
Subsequently, the model undergoes fine-tuning to align with human preferences, following a detailed methodology that we describe.


Bayesian Intrinsic Groupwise Image Registration: Unsupervised Disentanglement of Anatomy and Geometry
This article presents a general Bayesian learning framework for multi-modal groupwise registration on medical images.

IoT in the Era of Generative AI: Vision and Challenges
Equipped with sensing, networking, and computing capabilities, Internet of Things (IoT) such as smartphones, wearables, smart speakers, and household robots have been seamlessly weaved into our daily lives.

Grounding-Prompter: Prompting LLM with Multimodal Information for Temporal Sentence Grounding in Long Videos
To tackle these challenges, in this work we propose a Grounding-Prompter method, which is capable of conducting TSG in long videos through prompting LLM with multimodal information.
PokeMQA: Programmable knowledge editing for Multi-hop Question Answering
Multi-hop question answering (MQA) is one of the challenging tasks to evaluate machine's comprehension and reasoning abilities, where large language models (LLMs) have widely achieved the human-comparable performance.
LLM4VG: Large Language Models Evaluation for Video Grounding
Recently, researchers have attempted to investigate the capability of LLMs in handling videos and proposed several video LLM models.

In2SET: Intra-Inter Similarity Exploiting Transformer for Dual-Camera Compressive Hyperspectral Imaging
Dual-Camera Compressed Hyperspectral Imaging (DCCHI) offers the capability to reconstruct 3D Hyperspectral Image (HSI) by fusing compressive and Panchromatic (PAN) image, which has shown great potential for snapshot hyperspectral imaging in practice.
ConvD: Attention Enhanced Dynamic Convolutional Embeddings for Knowledge Graph Completion
In this paper, we propose a novel dynamic convolutional embedding model ConvD for knowledge graph completion, which directly reshapes the relation embeddings into multiple internal convolution kernels to improve the external convolution kernels of the traditional convolutional embedding model.
Efficient Large Language Models: A Survey
We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of efficient LLMs research and inspire them to contribute to this important and exciting field.
Detection and Mitigation of Position Spoofing Attacks on Cooperative UAV Swarm Formations
Detecting spoofing attacks on the positions of unmanned aerial vehicles (UAVs) within a swarm is challenging.
Virtual Quantum Markov Chains
In this work, we propose the concept of virtual quantum Markov chains (VQMCs), focusing on scenarios where subsystems retain classical information about global systems from measurement statistics.
VTimeLLM: Empower LLM to Grasp Video Moments
Large language models (LLMs) have shown remarkable text understanding capabilities, which have been extended as Video LLMs to handle video data for comprehending visual details.

 Dense Video Captioning
Video-based Generative Performance Benchmarking (Consistency)
+5
Dense Video Captioning
Video-based Generative Performance Benchmarking (Consistency)
+5
Out-of-Distribution Generalized Dynamic Graph Neural Network for Human Albumin Prediction
We first model human albumin prediction as a dynamic graph regression problem to model the dynamics and patient relationship.
A Generic Stochastic Hybrid Car-following Model Based on Approximate Bayesian Computation
However, the CF behavior of human drivers is highly stochastic and nonlinear.
OFDMA-F$^2$L: Federated Learning With Flexible Aggregation Over an OFDMA Air Interface
Federated learning (FL) can suffer from a communication bottleneck when deployed in mobile networks, limiting participating clients and deterring FL convergence.
Out-of-Distribution Generalized Dynamic Graph Neural Network with Disentangled Intervention and Invariance Promotion
In this paper, we propose Disentangled Intervention-based Dynamic graph Attention networks with Invariance Promotion (I-DIDA) to handle spatio-temporal distribution shifts in dynamic graphs by discovering and utilizing invariant patterns, i. e., structures and features whose predictive abilities are stable across distribution shifts.
Self-organized biodiversity in biotic resource systems
What determines biodiversity in nature is a prominent issue in ecology, especially in biotic resource systems that are typically devoid of cross-feeding.
Adversarial Prompt Tuning for Vision-Language Models
With the rapid advancement of multimodal learning, pre-trained Vision-Language Models (VLMs) such as CLIP have demonstrated remarkable capacities in bridging the gap between visual and language modalities.
Uni-COAL: A Unified Framework for Cross-Modality Synthesis and Super-Resolution of MR Images
Cross-modality synthesis (CMS), super-resolution (SR), and their combination (CMSR) have been extensively studied for magnetic resonance imaging (MRI).
MeLo: Low-rank Adaptation is Better than Fine-tuning for Medical Image Diagnosis
By fixing the weight of ViT models and only adding small low-rank plug-ins, we achieve competitive results on various diagnosis tasks across different imaging modalities using only a few trainable parameters.
UMedNeRF: Uncertainty-aware Single View Volumetric Rendering for Medical Neural Radiance Fields
In the field of clinical medicine, computed tomography (CT) is an effective medical imaging modality for the diagnosis of various pathologies.

Post-training Quantization with Progressive Calibration and Activation Relaxing for Text-to-Image Diffusion Models
In this paper, we propose a novel post-training quantization method PCR (Progressive Calibration and Relaxing) for text-to-image diffusion models, which consists of a progressive calibration strategy that considers the accumulated quantization error across timesteps, and an activation relaxing strategy that improves the performance with negligible cost.
Lightweight Diffusion Models with Distillation-Based Block Neural Architecture Search
When retraining the searched architecture, we adopt a dynamic joint loss to maintain the consistency between supernet training and subnet retraining, which also provides informative objectives for each block and shortens the paths of gradient propagation.
3D Pose Estimation of Tomato Peduncle Nodes using Deep Keypoint Detection and Point Cloud
A 21 comprehensive evaluation was conducted in a commercial greenhouse to gain insight into the 22 performance of different parts of the method.

Dissecting the Runtime Performance of the Training, Fine-tuning, and Inference of Large Language Models
For end users, our benchmark and findings help better understand different optimization techniques, training and inference frameworks, together with hardware platforms in choosing configurations for deploying LLMs.
VideoDreamer: Customized Multi-Subject Text-to-Video Generation with Disen-Mix Finetuning
The video generator is further customized for the given multiple subjects by the proposed Disen-Mix Finetuning and Human-in-the-Loop Re-finetuning strategy, which can tackle the attribute binding problem of multi-subject generation.
A Systematic Review for Transformer-based Long-term Series Forecasting
Various variants have enabled transformer architecture to effectively handle long-term time series forecasting (LTSF) tasks.

Towards Generalized Multi-stage Clustering: Multi-view Self-distillation
MVC aims at exploring common semantics and pseudo-labels from multiple views and clustering in a self-supervised manner.

Hierarchical Mutual Information Analysis: Towards Multi-view Clustering in The Wild
Multi-view clustering (MVC) can explore common semantics from unsupervised views generated by different sources, and thus has been extensively used in applications of practical computer vision.
Disentangled Representation Learning with Large Language Models for Text-Attributed Graphs
Text-attributed graphs (TAGs) are prevalent on the web and research over TAGs such as citation networks, e-commerce networks and social networks has attracted considerable attention in the web community.
LLM4DyG: Can Large Language Models Solve Spatial-Temporal Problems on Dynamic Graphs?
Our main observations are: 1) LLMs have preliminary spatial-temporal understanding abilities on dynamic graphs, 2) Dynamic graph tasks show increasing difficulties for LLMs as the graph size and density increase, while not sensitive to the time span and data generation mechanism, 3) the proposed DST2 prompting method can help to improve LLMs' spatial-temporal understanding abilities on dynamic graphs for most tasks.
Self-triggered Consensus Control of Multi-agent Systems from Data
In the presence of external disturbances, a model-based STC scheme is put forth for $\mathcal{H}_{\infty}$-consensus of MASs, serving as a baseline for the data-driven STC.
Provable Advantage of Parameterized Quantum Circuit in Function Approximation
To achieve this, we utilize techniques from quantum signal processing and linear combinations of unitaries to construct PQCs that implement multivariate polynomials.
Decentralized Federated Learning via MIMO Over-the-Air Computation: Consensus Analysis and Performance Optimization
We conduct a general convergence analysis to quantitatively capture the influence of aggregation weight and communication error on the MIMO OA-DFL performance in \emph{ad hoc} networks.
X-Transfer: A Transfer Learning-Based Framework for GAN-Generated Fake Image Detection
Generative adversarial networks (GANs) have remarkably advanced in diverse domains, especially image generation and editing.
Controlling Neural Style Transfer with Deep Reinforcement Learning
Controlling the degree of stylization in the Neural Style Transfer (NST) is a little tricky since it usually needs hand-engineering on hyper-parameters.
Improving Cross-dataset Deepfake Detection with Deep Information Decomposition
Deepfake technology poses a significant threat to security and social trust.
HoloAssist: an Egocentric Human Interaction Dataset for Interactive AI Assistants in the Real World
Building an interactive AI assistant that can perceive, reason, and collaborate with humans in the real world has been a long-standing pursuit in the AI community.
Statistical Analysis of Quantum State Learning Process in Quantum Neural Networks
As a quantum analog of probability distribution learning, quantum state learning is theoretically and practically essential in quantum machine learning.
Collaborative Watermarking for Adversarial Speech Synthesis
Advances in neural speech synthesis have brought us technology that is not only close to human naturalness, but is also capable of instant voice cloning with little data, and is highly accessible with pre-trained models available.


Image-to-Image Translation with Deep Reinforcement Learning
The key feature in the RL-I2IT framework is to decompose a monolithic learning process into small steps with a lightweight model to progressively transform a source image successively to a target image.

WiCV@CVPR2023: The Eleventh Women In Computer Vision Workshop at the Annual CVPR Conference
In this paper, we present the details of Women in Computer Vision Workshop - WiCV 2023, organized alongside the hybrid CVPR 2023 in Vancouver, Canada.
On-the-Fly SfM: What you capture is What you get
Over the last decades, ample achievements have been made on Structure from motion (SfM).

For A More Comprehensive Evaluation of 6DoF Object Pose Tracking
The limitations of previous scoring methods and error metrics are analyzed, based on which we introduce our improved evaluation methods.

Can large-scale vocoded spoofed data improve speech spoofing countermeasure with a self-supervised front end?
While many datasets use spoofed data generated by speech synthesis systems, it was recently found that data vocoded by neural vocoders were also effective as the spoofed training data.

Outlier Robust Adversarial Training
Theoretically, we show that the learning objective of ORAT satisfies the $\mathcal{H}$-consistency in binary classification, which establishes it as a proper surrogate to adversarial 0/1 loss.
Control-Oriented Modeling and Layer-to-Layer Spatial Control of Powder Bed Fusion Processes
However, due to inherent process variability, it is still very costly and time consuming to certify the process and the part.
DRAG: Divergence-based Adaptive Aggregation in Federated learning on Non-IID Data
Local stochastic gradient descent (SGD) is a fundamental approach in achieving communication efficiency in Federated Learning (FL) by allowing individual workers to perform local updates.
BenchTemp: A General Benchmark for Evaluating Temporal Graph Neural Networks
To handle graphs in which features or connectivities are evolving over time, a series of temporal graph neural networks (TGNNs) have been proposed.
Graph Meets LLMs: Towards Large Graph Models
In order to promote applying large models for graphs forward, we present a perspective paper to discuss the challenges and opportunities associated with developing large graph models.
A Survey on Fairness in Large Language Models
Large Language Models (LLMs) have shown powerful performance and development prospects and are widely deployed in the real world.
Unsupervised Multiplex Graph Learning with Complementary and Consistent Information
Unsupervised multiplex graph learning (UMGL) has been shown to achieve significant effectiveness for different downstream tasks by exploring both complementary information and consistent information among multiple graphs.
SphereNet: Learning a Noise-Robust and General Descriptor for Point Cloud Registration
However, most methods are susceptible to noise and have poor generalization ability on unseen datasets.
Mixed-Precision Quantization with Cross-Layer Dependencies
Quantization assigning the same bit-width to all layers leads to large accuracy degradation at low precision and is wasteful at high precision settings.
DisAsymNet: Disentanglement of Asymmetrical Abnormality on Bilateral Mammograms using Self-adversarial Learning
The question of 'what the symmetrical Bi-MG would look like when the asymmetrical abnormalities have been removed ?'
Unlocking the Potential of Deep Learning in Peak-Hour Series Forecasting
Unlocking the potential of deep learning in Peak-Hour Series Forecasting (PHSF) remains a critical yet underexplored task in various domains.
Prompt Tuning Pushes Farther, Contrastive Learning Pulls Closer: A Two-Stage Approach to Mitigate Social Biases
Meanwhile, experimental results on the GLUE benchmark show that CCPA retains the language modeling capability of PLMs.
Over-The-Air Federated Learning: Status Quo, Open Challenges, and Future Directions
The development of applications based on artificial intelligence and implemented over wireless networks is increasingly rapidly and is expected to grow dramatically in the future.
An Explainable Deep Framework: Towards Task-Specific Fusion for Multi-to-One MRI Synthesis
Multi-sequence MRI is valuable in clinical settings for reliable diagnosis and treatment prognosis, but some sequences may be unusable or missing for various reasons.
Synthesis of Contrast-Enhanced Breast MRI Using Multi-b-Value DWI-based Hierarchical Fusion Network with Attention Mechanism
DWIs with different b-values are fused to efficiently utilize the difference features of DWIs.
Textbooks Are All You Need
Despite this small scale, phi-1 attains pass@1 accuracy 50. 6% on HumanEval and 55. 5% on MBPP.
 Ranked #43 on
Code Generation
on HumanEval
Ranked #43 on
Code Generation
on HumanEval
Semantics-Aware Next-best-view Planning for Efficient Search and Detection of Task-relevant Plant Parts
Active vision is a promising approach to viewpoint planning, which helps robots to deliberately plan camera viewpoints to overcome occlusion and improve perception accuracy.
Towards single integrated spoofing-aware speaker verification embeddings
Second, competitive performance should be demonstrated compared to the fusion of automatic speaker verification (ASV) and countermeasure (CM) embeddings, which outperformed single embedding solutions by a large margin in the SASV2022 challenge.
Controllable Text-to-Image Generation with GPT-4
Control-GPT works by querying GPT-4 to write TikZ code, and the generated sketches are used as references alongside the text instructions for diffusion models (e. g., ControlNet) to generate photo-realistic images.

Range-Based Equal Error Rate for Spoof Localization
To properly measure misclassified ranges and better evaluate spoof localization performance, we upgrade point-based EER to range-based EER.
Integrating Listwise Ranking into Pairwise-based Image-Text Retrieval
Given a query caption, the goal is to rank candidate images by relevance, from large to small.
TOAST: Transfer Learning via Attention Steering
We introduce Top-Down Attention Steering (TOAST), a novel transfer learning algorithm that keeps the pre-trained backbone frozen, selects task-relevant features in the output, and feeds those features back to the model to steer the attention to the task-specific features.

Federated Learning Model Aggregation in Heterogenous Aerial and Space Networks
Direct sharing of the data distribution may be prohibitive due to the additional private information that is sent from the clients.
Gorilla: Large Language Model Connected with Massive APIs
Large Language Models (LLMs) have seen an impressive wave of advances recently, with models now excelling in a variety of tasks, such as mathematical reasoning and program synthesis.
Improving Generalization Ability of Countermeasures for New Mismatch Scenario by Combining Multiple Advanced Regularization Terms
The ability of countermeasure models to generalize from seen speech synthesis methods to unseen ones has been investigated in the ASVspoof challenge.
Efficient information recovery from Pauli noise via classical shadow
The rapid advancement of quantum computing has led to an extensive demand for effective techniques to extract classical information from quantum systems, particularly in fields like quantum machine learning and quantum chemistry.
DisenBooth: Identity-Preserving Disentangled Tuning for Subject-Driven Text-to-Image Generation
To tackle the problems, we propose DisenBooth, an identity-preserving disentangled tuning framework for subject-driven text-to-image generation.
Clothes Grasping and Unfolding Based on RGB-D Semantic Segmentation
These methods often utilize physics engines to synthesize depth images to reduce the cost of real labeled data collection.

DELTA: Dynamic Embedding Learning with Truncated Conscious Attention for CTR Prediction
To tackle this problem, inspired by the Global Workspace Theory in conscious processing, which posits that only a specific subset of the product features are pertinent while the rest can be noisy and even detrimental to human-click behaviors, we propose a CTR model that enables Dynamic Embedding Learning with Truncated Conscious Attention for CTR prediction, termed DELTA.

Enhancing Video Super-Resolution via Implicit Resampling-based Alignment
We show that bilinear interpolation inherently attenuates high-frequency information while an MLP-based coordinate network can approximate more frequencies.
 Ranked #1 on
Video Super-Resolution
on REDS4- 4x upscaling
Ranked #1 on
Video Super-Resolution
on REDS4- 4x upscaling

JaxPruner: A concise library for sparsity research
This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research.
LayerNAS: Neural Architecture Search in Polynomial Complexity
For a model architecture with $L$ layers, we perform layerwise-search for each layer, selecting from a set of search options $\mathbb{S}$.

Harnessing the Power of Text-image Contrastive Models for Automatic Detection of Online Misinformation
As growing usage of social media websites in the recent decades, the amount of news articles spreading online rapidly, resulting in an unprecedented scale of potentially fraudulent information.
A Clustering Framework for Unsupervised and Semi-supervised New Intent Discovery
New intent discovery is of great value to natural language processing, allowing for a better understanding of user needs and providing friendly services.
Arbitrary Reduction of MRI Inter-slice Spacing Using Hierarchical Feature Conditional Diffusion
Magnetic resonance (MR) images collected in 2D scanning protocols typically have large inter-slice spacing, resulting in high in-plane resolution but reduced through-plane resolution.

Adversarially Robust Neural Architecture Search for Graph Neural Networks
To tackle these challenges, we propose a novel Robust Neural Architecture search framework for GNNs (G-RNA).
CIMI4D: A Large Multimodal Climbing Motion Dataset under Human-scene Interactions
The core of this dataset is a blending optimization process, which corrects for the pose as it drifts and is affected by the magnetic conditions.
Domain Adaptive Semantic Segmentation by Optimal Transport
Second, we utilize OT to achieve a more robust alignment of source and target domains in output space, where the OT plan defines a well attention mechanism to improve the adaptation of the model.

Damage detection of high-speed railway box girder using train-induced dynamic responses
This paper proposes a damage detection method based on the train-induced responses of high-speed railway box girder.
Top-Down Visual Attention from Analysis by Synthesis
In this paper, we consider top-down attention from a classic Analysis-by-Synthesis (AbS) perspective of vision.
A Survey of Graph Prompting Methods: Techniques, Applications, and Challenges
In particular, we introduce the basic concepts of graph prompt learning, organize the existing work of designing graph prompting functions, and describe their applications and future challenges.
Optimal Beamforming for MIMO DFRC Systems with Transmit Covariance Constraints
Under this approach, we reveal that the optimal receive beamforming is given by the classic MMSE one and the optimal transmit beamforming design amounts to solving an orthogonal Procrustes problem, thereby allowing for closed-form solutions to subproblems in each BCD step and fast convergence of the proposed algorithm to a high-quality (near-optimal) overall beamforming design.
Selectively Hard Negative Mining for Alleviating Gradient Vanishing in Image-Text Matching
To alleviate the gradient vanishing problem, we propose a Selectively Hard Negative Mining (SelHN) strategy, which chooses whether to mine hard negative samples according to the gradient vanishing condition.
RIS-Assisted Jamming Rejection and Path Planning for UAV-Borne IoT Platform: A New Deep Reinforcement Learning Framework
This paper presents a new deep reinforcement learning (DRL)-based approach to the trajectory planning and jamming rejection of an unmanned aerial vehicle (UAV) for the Internet-of-Things (IoT) applications.

Unsupervised Deep Learning for IoT Time Series
IoT time series analysis has found numerous applications in a wide variety of areas, ranging from health informatics to network security.
Curriculum Graph Machine Learning: A Survey
To the best of our knowledge, this paper is the first survey for curriculum graph machine learning.
IMPORTANT-Net: Integrated MRI Multi-Parameter Reinforcement Fusion Generator with Attention Network for Synthesizing Absent Data
Then the multi-parameter fusion with attention module enables the interaction of the encoded information from different parameters through a set of algorithmic strategies, and applies different weights to the information through the attention mechanism after information fusion to obtain refined representation information.
Synthesis-based Imaging-Differentiation Representation Learning for Multi-Sequence 3D/4D MRI
Multi-sequence MRIs can be necessary for reliable diagnosis in clinical practice due to the complimentary information within sequences.
The Power of External Memory in Increasing Predictive Model Capacity
One way of introducing sparsity into deep networks is by attaching an external table of parameters that is sparsely looked up at different layers of the network.
Attacking Important Pixels for Anchor-free Detectors
Existing adversarial attacks on object detection focus on attacking anchor-based detectors, which may not work well for anchor-free detectors.
Decouple Before Interact: Multi-Modal Prompt Learning for Continual Visual Question Answering
Based on our formulation, we further propose MulTi-Modal PRompt LearnIng with DecouPLing bEfore InTeraction (TRIPLET), a novel approach that builds on a pre-trained vision-language model and consists of decoupled prompts and prompt interaction strategies to capture the complex interactions between modalities.

You Do Not Need Additional Priors or Regularizers in Retinex-Based Low-Light Image Enhancement
The Retinex-based methods require decomposing the image into reflectance and illumination components, which is a highly ill-posed problem and there is no available ground truth.

HDG-ODE: A Hierarchical Continuous-Time Model for Human Pose Forecasting
Considering the structural-property of the skeleton data in representing human poses and the possible irregularity caused by occlusion, we propose the use of dynamic graph convolution as the basic operator.

Understanding Zero-Shot Adversarial Robustness for Large-Scale Models
We apply this training loss to two adaption methods, model finetuning and visual prompt tuning.
Doubly Right Object Recognition: A Why Prompt for Visual Rationales
We propose a ``doubly right'' object recognition benchmark, where the metric requires the model to simultaneously produce both the right labels as well as the right rationales.

Hiding speaker's sex in speech using zero-evidence speaker representation in an analysis/synthesis pipeline
The use of modern vocoders in an analysis/synthesis pipeline allows us to investigate high-quality voice conversion that can be used for privacy purposes.
Object Detection in Foggy Scenes by Embedding Depth and Reconstruction into Domain Adaptation
In our DA framework, we retain the depth and background information during the domain feature alignment.
Disentangled Representation Learning
Disentangled Representation Learning (DRL) aims to learn a model capable of identifying and disentangling the underlying factors hidden in the observable data in representation form.
FedSiam-DA: Dual-aggregated Federated Learning via Siamese Network under Non-IID Data
Federated learning is a distributed learning that allows each client to keep the original data locally and only upload the parameters of the local model to the server.
Super-resolution Reconstruction of Single Image for Latent features
Single-image super-resolution (SISR) typically focuses on restoring various degraded low-resolution (LR) images to a single high-resolution (HR) image.
Shared Loss between Generators of GANs
Traditional GANs fall prey to the mode collapse problem, which means that they are unable to generate the different variations of data present in the input dataset.
LiDAL: Inter-frame Uncertainty Based Active Learning for 3D LiDAR Semantic Segmentation
We propose LiDAL, a novel active learning method for 3D LiDAR semantic segmentation by exploiting inter-frame uncertainty among LiDAR frames.
Large Language Models with Controllable Working Memory
By contrast, when the context is irrelevant to the task, the model should ignore it and fall back on its internal knowledge.
Lightweight Neural Network with Knowledge Distillation for CSI Feedback
Firstly, an autoencoder KD-based method is introduced by training a student autoencoder to mimic the reconstructed CSI of a pretrained teacher autoencoder.
Detection of Real-time DeepFakes in Video Conferencing with Active Probing and Corneal Reflection
Specifically, we authenticate video calls by displaying a distinct pattern on the screen and using the corneal reflection extracted from the images of the call participant's face.
RMBench: Benchmarking Deep Reinforcement Learning for Robotic Manipulator Control
Reinforcement learning is applied to solve actual complex tasks from high-dimensional, sensory inputs.
Spoofed training data for speech spoofing countermeasure can be efficiently created using neural vocoders
To make better use of pairs of bona fide and spoofed data, this study introduces a contrastive feature loss that can be plugged into the standard training criterion.
AdaGCL: Adaptive Subgraph Contrastive Learning to Generalize Large-scale Graph Training
To bridge the gap between large-scale graph training and contrastive learning, we propose adaptive subgraph contrastive learning (AdaGCL).
InFIP: An Explainable DNN Intellectual Property Protection Method based on Intrinsic Features
Since the intrinsic feature is composed of unique interpretation of the model's decision, the intrinsic feature can be regarded as fingerprint of the model.
GGViT:Multistream Vision Transformer Network in Face2Face Facial Reenactment Detection
The compression of videos on social media has destroyed some pixel details that could be used to detect forgeries.
Block Format Error Bounds and Optimal Block Size Selection
This measure allows us to determine the optimal parameters, such as the block size, yielding highest accuracy.
3D Matting: A Benchmark Study on Soft Segmentation Method for Pulmonary Nodules Applied in Computed Tomography
In this work, we introduce the image matting into the 3D scenes and use the alpha matte, i. e., a soft mask, to describe lesions in a 3D medical image.

STSyn: Speeding Up Local SGD with Straggler-Tolerant Synchronization
Synchronous local stochastic gradient descent (local SGD) suffers from some workers being idle and random delays due to slow and straggling workers, as it waits for the workers to complete the same amount of local updates.
Attention Augmented ConvNeXt UNet For Rectal Tumour Segmentation
It is a challenge to segment the location and size of rectal cancer tumours through deep learning.
Unified Loss of Pair Similarity Optimization for Vision-Language Retrieval
More specifically, Triplet loss with Hard Negative mining (Triplet-HN), which is widely used in existing retrieval models to improve the discriminative ability, is easy to fall into local minima in training.
3D Matting: A Soft Segmentation Method Applied in Computed Tomography
It can be caused by many factors, such as the imaging properties, pathological anatomy, and the weak representation of the binary masks, which brings challenges to accurate 3D segmentation.
MIntRec: A New Dataset for Multimodal Intent Recognition
This paper introduces a novel dataset for multimodal intent recognition (MIntRec) to address this issue.
 Ranked #1 on
Multimodal Intent Recognition
on MIntRec
Ranked #1 on
Multimodal Intent Recognition
on MIntRec
Joint Speaker Encoder and Neural Back-end Model for Fully End-to-End Automatic Speaker Verification with Multiple Enrollment Utterances
Conventional automatic speaker verification systems can usually be decomposed into a front-end model such as time delay neural network (TDNN) for extracting speaker embeddings and a back-end model such as statistics-based probabilistic linear discriminant analysis (PLDA) or neural network-based neural PLDA (NPLDA) for similarity scoring.
NeurIPS'22 Cross-Domain MetaDL competition: Design and baseline results
We present the design and baseline results for a new challenge in the ChaLearn meta-learning series, accepted at NeurIPS'22, focusing on "cross-domain" meta-learning.

NL2GDPR: Automatically Develop GDPR Compliant Android Application Features from Natural Language
At the core, NL2GDPR is a privacy-centric information extraction model, appended with a GDPR policy finder and a policy generator.
Data-Driven Control of Distributed Event-Triggered Network Systems
The present paper deals with data-driven event-triggered control of a class of unknown discrete-time interconnected systems (a. k. a.
Context-Aware Streaming Perception in Dynamic Environments
These works evaluate accuracy offline, one image at a time.
Efficient Climate Simulation via Machine Learning Method
We develop a user-friendly platform NeuroGCM for efficiently developing hybrid modeling in climate simulation.
GPPT: Graph Pre-training and Prompt Tuning to Generalize Graph Neural Networks
Based on the pre-trained model, we propose the graph prompting function to modify the standalone node into a token pair, and reformulate the downstream node classification looking the same as edge prediction.
Revisiting Adversarial Attacks on Graph Neural Networks for Graph Classification
Graph neural networks (GNNs) have achieved tremendous success in the task of graph classification and its diverse downstream real-world applications.

A Theoretical View on Sparsely Activated Networks
After representing LSH-based sparse networks with our model, we prove that sparse networks can match the approximation power of dense networks on Lipschitz functions.
Event-triggered Consensus Control of Heterogeneous Multi-agent Systems: Model- and Data-based Analysis
This article deals with model- and data-based consensus control of heterogenous leader-following multi-agent systems (MASs) under an event-triggering transmission scheme.
Trajectory Planning of Cellular-Connected UAV for Communication-assisted Radar Sensing
Being a key technology for beyond fifth-generation wireless systems, joint communication and radar sensing (JCAS) utilizes the reflections of communication signals to detect foreign objects and deliver situational awareness.
Proving Common Mechanisms Shared by Twelve Methods of Boosting Adversarial Transferability
This paper summarizes the common mechanism shared by twelve previous transferability-boosting methods in a unified view, i. e., these methods all reduce game-theoretic interactions between regional adversarial perturbations.
PanGu-Coder: Program Synthesis with Function-Level Language Modeling
We present PanGu-Coder, a pretrained decoder-only language model adopting the PanGu-Alpha architecture for text-to-code generation, i. e. the synthesis of programming language solutions given a natural language problem description.
Neural-Sim: Learning to Generate Training Data with NeRF
However, existing approaches either require human experts to manually tune each scene property or use automatic methods that provide little to no control; this requires rendering large amounts of random data variations, which is slow and is often suboptimal for the target domain.

Scene Recognition with Objectness, Attribute and Category Learning
Based on the complementarity of attribute and category labels, we propose a Multi-task Attribute-Scene Recognition (MASR) network which learns a category embedding and at the same time predicts scene attributes.
Rank-based Decomposable Losses in Machine Learning: A Survey
Following these categories, we review the literature on rank-based aggregate losses and rank-based individual losses.
Scaling Novel Object Detection with Weakly Supervised Detection Transformers
A critical object detection task is finetuning an existing model to detect novel objects, but the standard workflow requires bounding box annotations which are time-consuming and expensive to collect.

Unsupervised Domain Adaptive Fundus Image Segmentation with Category-level Regularization
Existing unsupervised domain adaptation methods based on adversarial learning have achieved good performance in several medical imaging tasks.
Enhanced brain structure-function tethering in transmodal cortex revealed by high-frequency eigenmodes
Specifically, low-frequency eigenmodes, which are considered sufficient to capture the essence of the functional network, contribute little to functional connectivity reconstruction in transmodal regions, resulting in structure-function decoupling along the unimodal-transmodal gradient.
NAS-Bench-Graph: Benchmarking Graph Neural Architecture Search
To the best of our knowledge, our work is the first benchmark for graph neural architecture search.
Concentration of Data Encoding in Parameterized Quantum Circuits
This result in particular implies that the average encoded state will concentrate on the maximally mixed state at an exponential speed on depth.
A Comprehensive Survey on Deep Clustering: Taxonomy, Challenges, and Future Directions
Motivated by the tremendous success of deep learning in clustering, one of the most fundamental machine learning tasks, and the large number of recent advances in this direction, in this paper we conduct a comprehensive survey on deep clustering by proposing a new taxonomy of different state-of-the-art approaches.
